Удаленный вызов процедур и рандеву
В данном разделе показано, как реализовать RPC и совместно используемые примитивы (включая рандеву) в ядре, а рандеву — с помощью асинхронной передачи сообщений. Ядро, поддерживающее RPC, иллюстрирует, как управлять двусторонним взаимодействием в ядре. На примере реализации рандеву с помощью передачи сообщений представлены дополнительные операции взаимодействия, необходимые для поддержки синхронизации в стиле рандеву. Ядро, обеспечивающее совместно используемые примитивы, демонстрирует реализацию всех различных примитивов взаимодействия одним унифицированным способом.
10.3.1. Реализация RPC в ядре
RPC поддерживает только взаимодействие и не заботится о синхронизации, поэтому реализуется проще всего. Напомним, что программа, использующая RPC, состоит из набора модулей, которые содержат процедуры и процессы. Процедуры (операции), объявленные в части определений модуля, можно вызывать из процессов, которые выполняются в других модулях. Все части модуля располагаются на одной машине, но разные модули могут находиться на разных машинах. (Здесь не рассматривается, как программист указывает размещение модуля; один из таких механизмов был описан в разделе 8.7.)
Процессы, выполняемые в одном модуле, взаимодействуют с помощью разделяемых переменных и синхронизируются, используя семафоры. Предполагается, что на каждой машине есть локальное ядро, реализующее процессы и семафоры, как описано в главе 6, и что ядра содержат процедуры сетевого интерфейса (см. листинг 10.2). Задача состоит в том, чтобы дополнить ядро процедурами и примитивами для реализации RPC.
Между вызывающим процедуру процессом и процедурой возможны три типа отношений.
• Они находятся в одном модуле и, следовательно, на одной машине.
• Они находятся в разных модулях, но на одной машине.
• Они находятся на разных машинах.
В первой ситуации можно использовать обычный вызов процедуры. Нет необходимости использовать ядро, если на этапе компиляции известно, что процедура является локальной.
Вы зывающий процедуру процесс может просто поместить аргументы в стек и перейти к выполнению процедуры, а после выхода из нее — извлечь из стека ее результаты и продолжить работу. Для межмодульных вызовов каждую процедуру можно однозначно идентифицировать парой (machine, address), где machine указывает место хранения тела процедуры, a address — точку входа в процедуру. Оператор вызова можно реализовать следующим образом.
if (machine локальная)
выполнить обычный вызов по адресу address ; else
rpc (machine, address, аргументы-значения);
388 Часть 2 Распределенное программирование
Для использования обычного вызова процедура обязательно должна существовать. Это условие выполняется, если нельзя изменять идентификатор процедуры или динамически уничтожать модули. В противном случае, чтобы перед вызовом процедуры убедиться в ее существовании, понадобится входить в локальное ядро.
Чтобы выполнить удаленный вызов процедуры, процесс должен передать на удаленную машину аргументы-значения и приостановить работу до получения результатов. Когда удаленная машина получает сообщение CALL, она создает процесс для выполнения тела процедуры. Перед завершением этого процесса вызывается примитив удаленного ядра, который передает результаты на первую машину.
В листинге 10.7 приведены ядровые примитивы для реализации rpc, а также новый обработчик прерывания чтения. В этих подпрограммах используется процедура распределенного ядра для асинхронной передачи сообщений netWrite (см. листинг 10.2), которая, в свою очередь, взаимодействует с соответствующим обработчиком прерывания.
При обработке удаленного вызова происходят следующие события.
• Вызывающий процесс инициирует примитив грс, который передает идентификатор вызывающего процесса, адрес процедуры и ее аргументы-значения на удаленную машину.
• Обработчик прерывания чтения в удаленном ядре получает сообщение и вызывает примитив handle_rpc, который создает процесс для обслуживания вызова.
• Серверный процесс выполняет тело процедуры и затем запускает примитив rpcRe-turn, чтобы возвратить результаты в ядро вызывающего процесса.
• Обработчик прерывания чтения в ядре вызывающего процесса получает возвращаемое сообщение и вызывает процедуру handleReturn, которая снимает блокировку вызывающей процедуры.
В примитиве handle_rpc предполагается, что существует список заранее созданных дескрипторов процессов, обслуживающих вызовы. Это ускоряет обработку удаленного вызова, поскольку не требует накладных расходов на динамическое выделение памяти и инициализацию дескрипторов. Также предполагается, что каждый серверный процесс запрограммирован так, что его первым действием является переход на соответствующую процедуру, а последним — вызов примитива ядра rpcReturn.


10.3.2. Реализация рандеву с помощью асинхронной передачи сообщений
Рассмотрим, как реализовать рандеву, используя асинхронную передачу сообщений. Напомним, что в рандеву участвуют два партнера: вызывающий процесс, который инициирует операцию с помощью оператора вызова, и сервер, обслуживающий операцию, используя оператор ввода. В разделе 7.3 было показано, как имитировать вызывающий процесс (клиент) и сервер с помощью асинхронной передачи сообщений (см. листинги 7.3 и 7.4). Здесь эта имитация развивается для реализации рандеву.
Главное — реализовать операторы ввода. Напомним, что оператор ввода содержит одну или несколько защищенных операций. Выполнение оператора in приостанавливает процесс до появления приемлемого вызова — оператор ввода обслужит тот вызов, для которого выполняется условие синхронизации. Пока не будем обращать внимания на выражения планирования.
Операцию можно обслужить только тем процессом, в котором она объявлена, поэтому ожидающие вызовы можно сохранить в этом процессе. Существует два основных способа сохранения вызовов' с отдельной очередью для каждой операции или с отдельной очередью для каждого процесса. (В действительности существует еще один вариант, который используется в следующем разделе по причинам, объясняемым здесь.) Используем способ с отдельной очередью для каждого процесса, поскольку это приводит к более простой реализации.
К тому же, во многих примерах главы 8 использовался один оператор ввода на серверный процесс. Однако у сервера может быть и несколько операторов ввода, обслуживающих разные операции. В таком случае появится необходимость просматривать вызовы, которые не могут быть выбраны в данном операторе ввода.
В листинге 10.8 иллюстрируется реализация рандеву с помощью асинхронной передачи сообщений. Каждый процесс с, выполняющий оператор вызова, имеет канал reply, из которого он получает результаты вызовов процедур. У каждого серверного процесса s, выполняющего оператор ввода, есть канал invoke, из которого он получает вызовы, и локальная очередь

Чтобы реализовать оператор ввода, серверный процесс S сначала просматривает ожидающие вызовы. Если он находит приемлемый вызов (операцию, соответствующую оператору вызова, для которой истинно условие синхронизации), то s удаляет самый старый из таких вызовов в очереди pending. Иначе S получает новые вызовы до тех пор, пока не найдет приемлемый вызов (сохраняя при этом неприемлемые). Найдя приемлемый вызов, S выполняет тело защищенной операции и после этого передает ответ вызвавшему процессу.
Напомним, что выражение планирования влияет на выбор вызова, если приемлемых вызовов несколько. Выражения планирования можно реализовать, дополнив листинг 10.8 следующим образом. Во-первых, чтобы планировать обработку ожидающих вызовов, серверный процесс должен сначала узнать обо всех таких вызовах. Это вызовы из очереди pending и других очередей, которые могут собираться в канале invoke процесса. Таким образом, перед просмотром очереди pending сервер S должен выполнить такой код.
while (not empty(invoke[S])) {
receive invoke[S](caller, opid, values);
вставить (caller, opid, values) в очередь pending; }
Во-вторых, если сервер находит приемлемый вызов в очереди pending, он должен просмотреть всю очередь в поисках приемлемого вызова этой же операции с минимальным значением выражения планирования.
Если такой вызов найден, то серверный процесс удаляет его из pending и обслуживает вместо первого найденного вызова. Однако цикл в листинге 10.8 изменять не нужно. Если в очереди pending нет приемлемых вызовов, то первый полученный сервером вызов как раз и будет иметь наименьшее значение выражения планирования.
Глава 10. Реализация языковых механизмов 39
10.3.3. Реализация совместно используемых примитивов в ядре
Рассмотрим реализацию в ядре совместно используемых примитивов (см. раздел 8.3) В ней свойства распределенных ядер для передачи сообщений и RPC сочетаются со свойст вами реализации рандеву с помощью асинхронной передачи сообщений. Она также иллюст рирует один из способов реализации рандеву в ядре.
Используя составную нотацию примитивов, операции можно вызывать двумя способами с помощью синхронных операторов вызова (call) и асинхронных— передачи (send). Об служивать операции можно тоже двумя способами, используя процедуры или операторы вво да (но не обоими одновременно). Таким образом, в ядре должно быть известно, какие методь используются для вызова и обслуживания каждой операции. Предположим, что ссылка н; операцию имеет вид записи с тремя полями. Первое поле указывает способ обработки операции. Второе определяет машину, на которой должна быть обслужена операция. Для операции, обслуживаемой процедурой ргос, третье поле записи указывает точку входа процедурь в ядре для RPC. Если же операция обслуживается операторами ввода, третье поле содержи! адрес дескриптора операции (его содержимое уточняется через два абзаца).
В рандеву каждая операция обслуживается тем процессом, в котором она объявлена. Следовательно, в реализации рандеву используется по одному набору ожидающих вызовов на каждый серверный процесс. Однако при использовании составной нотации примитивов операцию можно обслуживать операторами ввода в нескольких процессах модуля, в котором она объявлена.
Таким образом, серверным процессам одного модуля может понадобиться совместный доступ к ожидающим вызовам. Можно реализовать одно множество ожидающих вызовов для каждого модуля, но тогда все процессы модуля должны будут соперничать в доступе к этому множеству, даже если они обслуживают разные операции. Это приведет к задержкам, связанным с ожиданием доступа ко множеству и просмотром вызовов, которые наверняка не могут быть обслужены. Поэтому для ожидающих вызовов используем несколько множеств, по одному для каждого класса операций, как определено ниже.
Класс операции — это класс эквивалентности транзитивного замыкания отношения "обслуживаются одним и тем же оператором ввода". Например, если в одном операторе ввода есть операции а и Ь, то они принадлежат одному классу. Если в другом операторе ввода (в этом же модуле) есть операции а и с, то операция с также принадлежит классу, содержащему а и Ь. В худшем случае все операции модуля принадлежат одному классу. В лучшем — каждая находится в своем классе (например, если все они обслуживаются операторами receive).
Ссылка на операцию, которую обслуживают операторы ввода, содержит указатель на дескриптор операции. Дескриптор операции, в свою очередь, содержит указатель на дескриптор класса операции. Оба дескриптора хранятся на машине, обслуживающей эту операцию. Дескриптор класса содержит следующую информацию:
блокировка — используется для взаимоисключающего доступа; список задержанных — задержанные вызовы операций данного класса; список новых — вызовы, пришедшие, пока класс был заблокирован; список доступа — процессы, ожидающие блокировки; список ожидания — процессы, ожидающие появления новых вызовов.
Блокировка используется для того, чтобы в любой момент времени только один процесс мог просматривать ожидающие вызовы. Использование других полей описано ниже.
Операторы вызова и передачи реализуются следующим образом. Если операцию обслуживает процедура, которая находится на той же машине, то оператор вызова преобразуется в прямой вызов процедуры.
Процесс может определить это, просмотрев поля описанной выше ссылки на операцию. Если операция относится к другой машине или обслуживается опе-
i
392 Часть 2. Распределенное программирование
раторами ввода, то оператор вызова запускает на локальной машине примитив invoke. Независимо от того, как обслуживается операция, оператор send выполняет примитив invoke.
Листинг 10.9 содержит код примитива invoke и двух процедур ядра, которые он использует. Первый аргумент определяет вид вызова. При вызове CALL ядро блокирует выполняемый процесс до завершения обслуживания вызова. Затем ядро определяет, на локальной или удаленной машине должна быть обслужена операция. Если на удаленной, ядро отсылает сообщение INVOKE удаленному ядру, выполняющему затем процедуру ядра locallnvoke.
Подпрограмма locallnvoke проверяет, процедурой ли обслуживается операция. Если да, то она получает свободный дескриптор процесса и дает серверному процессу указание выполнить процедуру, как в ядре для RPC. Ядро также записывает в дескрипторе, как вызывалась операция. Эти данные используются позже для определения, есть ли вызвавший процедуру процесс, который нужно запустить после выхода из нее.


Если операция обслуживается оператором ввода, процедура local Invoke проверяет дескриптор класса. Если класс заблокирован (процесс выполняет оператор ввода и проверяет задержанные вызовы), ядро сохраняет вызов в списке новых вызовов и перемещает все процессы, ожидающие новых вызовов, в список доступа к классу. Если класс не заблокирован, ядро добавляет вызов ко множеству задержанных вызовов и проверяет список ожидания. (Список доступа пуст, если класс не заблокирован.) Если есть процессы, ожидающие новых вызовов, то один из них запускается, устанавливается блокировка, а остальные ожидающие процессы перемещаются в список доступа.
Заканчивая выполнение процедуры, процесс вызывает примитив ядра procDone (листинг 10.10).
Этот примитив освобождает дескриптор процесса и запускает вызвавший процедуру процесс (если такой есть). Примитив awakenCaller выполняется ядром на той машине, на которой размещен вызывающий процесс.

• Для операторов ввода процесс выполняет код, приведенный в листинге 10.11. В этом коде вызываются примитивы оператора ввода (листинг 10.12).'Процесс сначала получает исключительный доступ к дескриптору класса операции и затем ищет приемлемые задержанные вызовы. Если ни один из них принять нельзя, процесс вызывает процедуру waitNew, чтобы приостановить работу до прихода нового вызова. Этот примитив может закончиться немедленно, если новый вызов приходит во время поиска задержанных вызовов (и, следовательно, при заблокированном дескрипторе класса).
Найдя приемлемый вызов, процесс выполняет соответствующую защищенную операцию и вызывает процедуру inDone. Ядро запускает вызвавший процедуру процесс (если он есть)
394 Часть 2 Распределенное программирование
и обновляет состояние дескриптора класса Если во время выполнения оператора ввода прибывают новые вызовы, они перемещаются в список задержанных, а процессы, ожидающие доступа к классу, перемещаются в список доступа Затем, если есть процессы, ожидающие доступ к классу, запускается один из них, иначе блокировка снимается.


396 Часть 2. Распределенное программирование
сообщений. Частично это связано с тем, что понятие разделяемых переменных близко последовательному программированию. Однако РРП требует дополнительных затрат на обработку ситуаций, связанных с отсутствием страниц в локальной памяти, а также на получение и передачу удаленных страниц.
Ниже описана реализация РРП, которая сама по себе является еще одним примером распределенной программы. Затем рассматриваются некоторые из общепринятых протоколов согласования страниц и то, как они поддерживают схемы доступа к данным в прикладных программах.
10.4.1. Обзор реализации
РРП — это программная прослойка между прикладными программами и операционной системой или специализированным ядром. Ее общая структура показана на рис. 10.3. Адресное пространство каждого процессора (узла) состоит из разделяемой и скрытой областей. Разделяемые переменные прикладной программы хранятся в разделяемой области, а код и скрытые данные — в скрытой. Таким образом, можно считать, что в разделяемой области памяти находится "куча" программы, а в скрытой — сегменты кода и стеки процессов. В скрытой области каждого узла также расположена копия программного обеспечения РРП и операционная система узла или ядро взаимодействия.
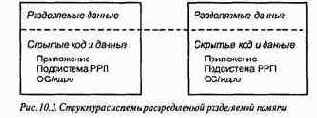
РРП управляет разделяемой областью адресного пространства. Это линейный массив байтов, который теоретически дублируется на каждом узле. Разделяемая область памяти разбивается на модули, каждый из которых защищается отдельно и находится на одном или нескольких узлах. Обычно модули являются страницами фиксированного размера, хотя они могут быть и страницами переменного размера или отдельными объектами данных. Здесь предполагается, что размеры модулей зафиксированы. Управление страницами аналогично управлению страничной виртуальной памятью одиночного процессора. Страница может быть или резидентной (присутствующей) или нет. Резидентная страница может быть доступной только для чтения или для чтения и записи.
Каждая разделяемая переменная в приложении отображается в адрес в разделяемой области памяти и, следовательно, имеет один и тот же адрес на всех узлах. Вначале страницы разделяемой области некоторым образом распределены по узлам. Пока будем считать, что существует одна копия каждой страницы, и страница доступна для чтения и записи на узле ее расположения.
Обращаясь к разделяемой переменной в резидентной странице, процесс получает к ней прямой доступ. Но обращение к нерезидентной странице приводит к ошибке обращения к странице. Эту ошибку обрабатывает программное обеспечение РРП.
Оно определяет расположение страницы и отправляет сообщение на запросивший ее (первый) узел. Второй узел (на котором была страница) помечает ее как нерезидентную и передает на первый узел. Первый узел, получив страницу, обновляет ее защиту и возвращается к прикладному процессу. Как и в системе виртуальной памяти, прикладной процесс повторно выполняет инструкцию, вызвавшую ошибку обращения к странице, и обращение к разделяемой переменной заканчивается успешно.
Для иллюстрации описанных выше действий рассмотрим следующий простой пример.

Процессы могли бы работать синхронно или в произвольном порядке, но предположим, что Р1 выполняется первым и присваивает х. Поскольку страница с х в данный момент находится на узле 1, запись выполняется успешно и процесс завершается. Теперь начинается Р2. Он пытается записать в у, но содержащая у страница нерезидентная, и возникает ошибка. Обработчик ошибки узла 2 передает запрос страницы на узел 1, который отсылает страницу узлу 2. Получив страницу, узел 2 запускает процесс Р2; теперь запись в у завершается успешно. В заключительном состоянии страница является резидентной для узла 2 и обе переменные имеют новые значения.
Когда РРП реализуется на основе операционной системы Unix, защита разделяемых страниц устанавливается системным вызовом mprotect. Защита резидентной страницы устанавливается в состояние read или READ и WRITE. Защита нерезидентных страниц устанавливается в состояние none. При запросе нерезидентной страницы вырабатывается сигнал о нарушении сегментации (sigsegv). Обработчик ошибок обращения к страницам в РРП получает этот сигнал и посылает сообщение о запросе страницы, используя примитивы взаимодействия Unix (или им подобные программы). По прибытии сообщения на узел генерируется сигнал ввода-вывода (SIGIO). Обработчик сигналов ввода-вывода определяет тип сообщения (запрос страницы или ответ) и предпринимает соответствующие действия. Обработчики сигналов должны выполняться в критических секциях, поскольку во время обработки одного сигнала может прийти другой, например во время обработки ошибки обращения к странице может прийти запрос на страницу.
РРП может быть однопоточной или многопоточной. Однопоточная РРП поддерживает только один прикладной процесс на каждом узле. Процесс, вызвавший ошибку обращения к странице, приостанавливается до разрешения ошибки. Многопоточная РРП поддерживает несколько приложений на каждом узле, поэтому, когда один процесс вызывает ошибку обращения к странице, другой может выполняться, пока первый ожидает разрешения ошибки. Однопоточную РРП реализовать проще, поскольку в ней меньше критических секций. Однако многопоточная РРП гораздо лучше скрывает задержки при обращениях к удаленной странице и, следовательно, может обеспечить более высокую производительность.
398 Часть 2. Распределенное программирование
10.4.2. Протоколы согласования страниц
Производительность приложения, выполняемого на базе РРП, зависит от эффективности реализации самой РРП. Сюда входят и возможность маскирования ожидания при доступе к памяти, и эффективность обработчиков сигналов, и, в особенности, свойства протоколов взаимодействия. Производительность приложения также существенно зависит от методов управления страницами, а именно — от используемого протокола согласования страниц. Далее описаны три таких протокола: блуждания, или переноса (migratory), денонсирующей записи (write invalidate) и совместной записи (write shared).
В примере в листинге 10.4 предполагалось, что существует одна копия каждой страницы. Когда страница нужна другому узлу, копия перемещается. Это называется протоколом переноса. Содержание страницы всегда согласованно, поскольку есть только одна ее копия. Но что случится, когда два процесса на двух узлах просто захотят прочесть переменную на этой странице? Тогда страница будет прыгать между ними; этот процесс называется замусориванием (trashing).
Протокол денонсирующей записи позволяет дублировать страницы при чтении. У каждой страницы есть владелец. Пытаясь прочитать удаленную страницу, процесс получает от ее _владельца неизменяемую копию (только для чтения).
Копия владельца на это время тоже помечается как доступная только для чтения. Пытаясь записать в страницу, процесс получает копию (при необходимости), делает недействительными (денонсирует) остальные копии и записывает в полученную страницу. Обработчик ошибки обращения к странице узла, выполняющего запись, при этом совершает следующие действия: 1) связывается с владельцем, 2) получает страницу и владение ею, 3) отправляет денонсирующие сообщения узлам, на которых есть копии этой страницы (они устанавливают защиту своей копии страницы в состояние NONE), 4) устанавливает защиту своей копии в состояние READ и WRITE, 5) возобновляет прикладной процесс.
Протокол денонсирующей записи очень эффективен для страниц, которые доступны только для чтения (после их инициализации) или редко изменяются. Однако при появлении ложного разделения этот протокол приводит к замусориванию. Вернемся к рис. 10.4. Переменные х и у не разделяются процессами, но находятся на одной разделяемой странице. Следовательно, эта страница будет перемещаться между двумя узлами так же, как и при использовании протокола переноса.
Ложное разделение можно исключить, размещая такие переменные, как х и у в примере на разных страницах. Это можно делать статически во время компиляции программы или динамически во'время выполнения. Вместе с тем, ложное разделение можно допустить, используя протокол совместной записи. Этот процесс позволяет выполнять несколько параллельных записей на одну страницу. Например, когда процесс Р2, выполняемый на узле 2 (см. рис. 10.4), записывает в у, узел 2 получает копию страницы от узла 1, и оба узла получают разрешение записать на эту страницу. Ясно, что копии становятся несогласованными. В таких точках синхронизации, определенных в приложении, как барьеры, копии объединяются. При ложном разделении страницы объединенная копия будет правильной и согласованной. Однако при действительном разделении объединенная копия будет неопределенной комбинацией записанных значений.
Для обработки таких ситуаций каждый узел поддерживает список изменений, сделанных им на странице с совместной записью. Эти списки используются при объединении копий для учета последовательности записей, сделанных разными процессами.
Историческая справка
Реализации примитивов взаимодействия существовали столько же, сколько и сами примитивы. В исторических справках к главам 7—9 упоминались статьи с описаниями новых примитивов; во многих из этих работ представлена и реализация примитивов. Два хороших
Глава 10 Реализация языковых механизмов 399
источника информации по данной теме— книги [Bacon, 1998] и [Tanenbaum, 1992]. В них описаны примитивы взаимодействия и вопросы их реализации в целом, рассмотрены примеры важных операционных систем.
В распределенном ядре (раздел 10.1) предполагалось, что передача по сети происходит без ошибок, и не учитывалось управление буферами и потоками. Решение этих вопросов представлено в книгах по компьютерным сетям, например [Tanenbaum, 1988] или [Paterson and Davie, 1996].
Централизованная реализация синхронной передачи сообщений (см. рис. 10.2, листинги 10.5 и 10.6) была разработана автором этой книги. Существуют и децентрализованные решения без центрального управляющего. В работе [Silberschatz, 1979] рассмотрены процессы, образующие кольцо, а в [Van de Snepscheut, 1981] — иерархические системы. В [Bernstein, 1980] представлена реализация, работающая при любой топологии связи, а в [Schneider, 1982] — алгоритм рассылки, который, по существу, повторяет множества ожидания нашего учетного процесса (листинг 10.6). Алгоритм Шнейдера прост и справедлив, но требует обмена большим количеством сообщений, поскольку каждый процесс должен подтверждать каждую передачу. В статье [Buckley and Silberschatz, 1983] предложен справедливый децентрализованный алгоритм, обобщающий алгоритм из [Bernstein, 1980]. Этот алгоритм эффективнее, чем алгоритм Шнейдера, но намного сложнее. (Все упомянутые алгоритмы описаны в книге [Raynal, 1988].) В работе [Bagrodia, 1989] представлен еще один алгоритм, более простой и эффективный, чем алгоритм из [Buckley and Silberschatz, 1983].
В разделе 10. 3 были представлены реализации рандеву с использованием асинхронной передачи сообщений и ядра. Из-за сложности механизма рандеву его производительность в целом ниже, чем других механизмов синхронизации. Во многих программах рандеву можно заменить более простыми механизмами, такими как процедуры и семафоры. Многочисленные примеры таких преобразований (для языка Ада) приведены в статье [Roberts et al., 1981]. В [McNamee and Olsson, 1990] представлено больше преобразований и проведен анализ получаемого роста производительности, который в некоторых случаях достигал 95 процентов.
Концепцию распределенной разделяемой памяти (РРП) разработал Кай Ли (Kai Li) в свой докторской диссертации в Йельском университете под руководством Пола Хьюдака (Paul Hu-dak). В статье [Li and Hudak, 1989] представлен протокол денонсирующей записи для согласования страниц. Ли внес решающий вклад в развитие этой темы, поскольку до его публикации никто не верил, что с помощью передачи сообщений можно моделировать разделяемую память с приемлемой производительностью. Теперь РРП занимает прочные позиции и даже поддерживается многими производителями суперкомпьютеров.
Две важнейшие из последних РРП-систем — Munin и TreadMarks, разработанные в университете Раиса (Rice). Реализация и производительность системы Munin, в которой появился протокол совместной записи, описана в статье [Carter, Bennett and Zwaenepoel, 1991], а система TreadMarks— в [Amza et al., 1996]. Производительность PVM и TreadMarks сравнивается в работе [Lu et al., 1997]. Книга [Tanenbaum, 1995] содержит отличный обзор по РРП, включая работу Ли, систему Munin и другие. За более новой информацией по вопросам РРП обращайтесь к специализированному изданию Proceedings of IEEE (март 1999).
Литература
Amza, С., A. L. Cox, S. Dwarkadas, P. Keleher, H. Lu, R. Rajamony, W. Yu, and W. Zwaenepoel. 1996. TreadMarks: Shared memory computing on networks of workstations. IEEE Computer 29, 2 (February): 18-28.
