Точечные вычисления
Сеточные вычисления обычно используются для моделирования непрерывных систем, которые описываются дифференциальными уравнениями в частных производных. Для моделирования дискретных систем, состоящих из отдельных частиц (точек), воздействующих друг на друга, применяются точечные методы. Примерами являются заряженные частицы, взаимодействующие с помощью электрических и магнитных сил, молекулы (их взаимодействие обусловлено химическим строением) и астрономические тела, воздействующие друг на друга благодаря гравитации. Здесь рассматривается типичное приложение, называемое гравитационной задачей п тел. После постановки задачи представлены последовательная и параллельная программы, основанные на алгоритме сложности О(«2), затем описаны два приближенных метода сложности 0(п Iog2n): метод Барнса—Хата (Barnes—Hut) и быстрый метод мультиполей.
11.2.1. Гравитационная задача п тел
Предположим, что дано большое число астрономических тел галактики (звезд, пылевых облаков и черных дыр), и нужно промоделировать ее эволюцию.


Глава 11. Научные вычисления 425
11.2.2. Программа с разделяемыми переменными
Рассмотрим, как распараллелить программу для задачи п тел. Как всегда, вначале нужно решить, как распределить работу. Предположим, что есть PR процессоров, и, следовательно, будут использованы PR рабочих процессов. В реальных задачах п намного больше PR. Предположим, что п кратно pr.
Большая часть расчетов в последовательной программе проводится в цикле for процедуры calculateForces. В методе итераций Якоби работа просто распределялась по полосам, и на каждый рабочий процесс приходилось по n/PR строк сетки. В результате вычислительная нагрузка была сбалансированной, поскольку по методу итераций Якоби в каждой точке сетки выполняется один и тот же объем работы.
Для задачи п тел соответствующим разделением было бы назначение каждому рабочему процессу непрерывного блока тел: процесс 1 обрабатывает первые n/PR тел, 2— следующие n/PR тел и т.д.
Однако это привело бы к слишком несбалансированной нагрузке. Процессу 1 придется вычислить силы взаимодействия тела 1 со всеми остальными, затем — тела 2 со всеми, кроме тела 1, и т.д. С другой стороны, последнему процессу нужно вычислить только те силы, которые не были вычислены предыдущими процессами, т.е. лишь между последними n/PR телами.
Пусть для конкретного примера п равно 8, a pr — 2, т.е. используются два рабочих процесса. Назовем их черным (black — в) и белым (white — W). На рис. 11.4 показаны три способа назначения тел процессам. При блочном распределении первые четыре тела назначаются процессу В, последние четыре — W. Таким образом, число пар сил, вычисляемых В, равно 22 (7 + 6 + 5+4), а вычисляемых W, — 6 (3 + 2 +1).

Вычислительная нагрузка будет более сбалансированной, если назначать тела иначе: 1 — процессу В, 2 — W, 3 — В и т.д. Эта схема называется распределением по полосам по аналогии с полосами зебры. (Она называется еще циклическим распределением, поскольку схема повторяется.) Распределение по полосам приводит к следующей нагрузке процессов: 16 пар сил для В и 12 — для W.
Нагрузку можно еще больше сбалансировать, если распределить тела по схеме, похожей на ту, которая обычно используется при выборе команд в спортивных играх: назначим тело 1 процессу В, тела 2 и 3 — W, тела 4 и 5 — В и т.д. Эта схема называется распределением по обратным полосам, поскольку полосы каждый раз меняют порядок: черный, белый; белый, черный; черный, белый и т.д. Например, на рис. 11.4 нагрузка полностью сбалансирована — по 14 пар сил на каждый процесс.
Любая из приведенных выше стратегий распределения легко обобщается на любое число pr рабочих процессов. Блочная стратегия тривиальна. Для полос используется PR различных цветов. Первым цветом окрашивается тело 1, вторым — тело 2 и т.д. Цикл повторяется, пока все тела не будут окрашены. При использовании обратных полос порядок цветов меняется, когда начинается новый цикл, т.е. после окраски pr тел.
Для этой и любой другой задачи с похожей схемой индексов в главном вычислительном цикле распределение данных по схеме обратных полос дает наиболее сбалансированную вычислительную нагрузку. Однако схема полос программируется намного легче, чем схема обратных полос, и для больших значений п дает практически сбалансированную нагрузку. Поэтому в дальнейшем используем схему полос.
426 Часть 3. Синхронное параллельное программирование
Следующие вопросы связаны с синхронизацией. Есть ли критические секции? Нужна ли барьерная синхронизация? Ответ на оба вопроса утвердительный.
Сначала рассмотрим процедуру calculateForces. В цикле for рассматривается каждая пара тел i и j. Пока один процесс вычисляет силы между телами i и j, другой вычисляет силы между телами i' и j '. Некоторые из этих номеров могут быть равными: например, j в одном процессе может совпадать с i' в другом. Следовательно, процессы могут мешать друг другу при обновлении вектора сил f. Таким образом, четыре оператора присваивания, обновляющих f, образуют код критической секции.
Один из способов защитить критическую секцию — использовать одну переменную блокировки. Однако это неэффективно, поскольку критическая секция выполняется много раз каждым процессом. В другом предельном случае можно использовать массив переменных блокировки, по одной на тело. Это почти устраняет конфликты при блокировке, но за счет использования гораздо большего объема памяти. Промежуточный способ — использовать одну переменную блокировки на каждый блок из в тел, но и тут возникают конфликты блокировки.
Для хорошей производительности лучше всего вообще устранить накладные расходы на блокировку, избавившись от критических секций (если возможно). Это можно сделать двумя способами. При первом каждый рабочий процесс берет на себя полную ответственность за назначенные ему тела, т.е. процесс, отвечающий за тело i, вычисляет все силы, действующие на тело i, но не обновляет вектор сил для любого другого тела j.
Взамен, процесс, отвечающий за тело j, вычисляет все силы, действующие на него, в том числе и со стороны тела i. Такой способ можно запрограммировать, используя индексную переменную j в for цикле calculateForces со значениями в диапазоне от 1 до п, а не от i+1 до п, и исключая присваивания f [ j ]. Однако при этом не используется симметричность сил между двумя телами, так что все силы вычисляются дважды.
Второй способ устранения критических секций — вектор сил заменить матрицей сил, каждая строка которой соответствует одному процессу. Вычисляя силу между телами i и j, процесс w обновляет два элемента своей строки в матрице сил. А когда нужно будет вычислить новые положение и скорость тела, он сначала сложит все силы, действующие на данное тело и вычисленные ранее всеми остальными процессами.
Оба способа устранения критических секций используют дублирование. В первом методе дублируются вычисления, во втором — данные. Это еще один пример пространственно-временного противоречия. Поскольку целью параллельной программы обычно является уменьшение времени выполнения, то лучший выбор — использовать как можно больше пространства (разумеется, в пределах доступной памяти).
Осталось рассмотреть еще один важный момент — нужны ли барьеры, и если да, то где именно. Значения новых скоростей и положений, вычисляемых в moveBodies, зависят от сил, вычисленных в calculateForces. Поэтому, пока не будут вычислены все силы, нельзя перемещать тела. Аналогично силы зависят от положений и скоростей, поэтому нельзя пересчитывать силы, пока не перемещены тела. Таким образом, после каждого вызова процедур calculateForces и moveBodies нужна барьерная синхронизация.
Итак, здесь описаны три способа назначения тел процессам. Использование схемы полос приводит к вполне сбалансированной и легко программируемой вычислительной нагрузке. Рассмотрена проблема критической секции, показано, как применять блокировку и избегать ее. Наиболее эффективен следующий подход: исключить критические секции, чтобы каждый процесс обновлял свой собственный вектор сил.
Наконец, независимо от распределения рабочей нагрузки и управления критическими секциями нужны барьеры после вычисления сил и перемещения тел.
Все представленные решения включены в код в листинге 11.7. В основном структура программы совпадает со структурой последовательной программы (см. листинг 11.6). Для реализации барьерной синхронизации добавлена третья процедура barrier. Единый главный цикл имитации заменен имитацией на PR рабочих процессорах, и каждый из них выполняет цикл имитации. Процедура barrier вызывается после как вычисления сил, так и перемещения тел. Во всех вызовах процедур содержится аргумент w, который указывает на вызывающий процесс.

428 Часть 3. Синхронное параллельное программирование
Тела процедур, вычисляющих силы и перемещающих тела, изменены так, как описано выше. Наконец, главные циклы в этих процедурах изменены так, что приращение по i равно PR, а не 1 (этого достаточно, чтобы присваивать тела рабочим по схеме полос). Код в листинге 11.7 можно сделать более эффективным, оптимизировав его, как и последовательную программу.
11.2.3. Программы с передачей сообщений
Рассмотрим, как решить задачу п тел, используя передачу сообщений. Нам нужно построить метод распределения вычислений между рабочими процессами, чтобы рабочая нагрузка была сбалансированной. Необходимо также минимизировать накладные расходы на взаимодействие или хотя бы снизить их по сравнению с объемом полезной работы. Эти проблемы непросты, поскольку в задаче « тел вычисляются силы для всех пар тел, и, следовательно, каждому процессу приходится взаимодействовать со всеми остальными.
Вначале полезно разобраться, можно ли использовать парадигмы взаимодействия между процессами, описанные в начале главы 9, — "управляющий-рабочие" (распределенный портфель задач), алгоритм пульсации и конвейер. Поскольку задачи достаточно хорошо определены, а нагрузку сбалансировать сложно, подходит парадигма "управляющий-рабочие".
Можно также применить алгоритм пульсации, используя распределение тел и обмен данными между процессами. Однако явно не достаточно того, что каждый процесс обменивается информацией только с одним или двумя соседями. Наконец, можно использовать конвейер, в котором тела переходят от процесса к процессу. Ниже приведены решения задачи п тел с помощью каждой из этих парадигм, затем обсуждаются их преимущества и недостатки.
Программа типа "управляющий-рабочие"
Применим парадигму "управляющий-рабочие" (см. раздел 9.1). Управляющий обслуживает портфель задач; рабочие многократно получают задачу, выполняют ее и возвращают результат управляющему. В задаче п тел есть две фазы. В задачах первой фазы вычисляются силы между всеми парами тел, в задачах второй — перемещаются тела. Вычисление сил является основной частью работы, которая может оказаться несбалансированной. Поэтому есть смысл при вычислении сил использовать динамические задачи, а и при перемещении тел — статические (по одной на рабочего).
Предположим, что у нас есть PR процессоров и используются PR рабочих процессов. (Управляющий процесс работает на том же процессоре, что и один из рабочих.) Предположим для простоты, что п кратно PR. При использовании парадигмы "управляющий-рабочие" для сбалансированности нагрузки нужно, чтобы задач было хотя бы вдвое больше, чем рабочих процессов. Однако очень большое число задач или рабочих процессов нежелательно, поскольку рабочие процессы потратят слишком много времени на взаимодействие с менеджером. Один из способов распределить вычисления сил, действующих на n тел, состоит в следующем.
Множество тел разделяется на PR блоков размером n/PR. Первый блок содержит первые n/ PR тел, второй — следующие n/PR тел и т.д.
Образуются пары (i,J) для всех возможных комбинаций номеров блоков. Таких пар будет PR* (PR+1) /2 (сумма целых чисел от 1 до pr).
Пусть каждая пара представляет задачу, например, для пары (i,f) — вычислить силы, действующие между телами в блоках i hj.
В качестве конкретного примера предположим, что pr равно 4. Тогда десять задач представлены парами
(1, 1), (1, 2), (1, 3), (1,4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4).
Глава 11. Научные вычисления 429
этого рабочему нужны данные о положениях, скоростях и массах тел в одном или двух блоках. Управляющий мог бы передавать эти данные вместе с задачей, но можно значительно сократить длину сообщений, если у каждого рабочего процесса будет своя собственная копия данных о всех телах. Аналогично можно избавиться и от необходимости отправлять результаты управляющему, если каждый рабочий процесс отслеживает силы, которые он вычислил для каждого тела.
После вычисления всех сил, т.е. когда портфель задач пуст, рабочим процессам нужно обменяться силами и затем переместить тела. Простейшее статическое назначение работы в фазе перемещения тел состоит в том, чтобы каждый рабочий перемещал тела в одном блоке: рабочий процесс 1 перемещает тела в блоке 1, рабочий 2 — в блоке 2 и т. д. Следовательно, каждому рабочему w нужны векторы сил для тел блока w.

430 Часть 3. Синхронное параллельное программирование
Собирать и распределять силы, вычисленные каждым рабочим процессом, мог бы управляющий, но эффективность повысится, если каждый рабочий будет отправлять силы для блока тел непосредственно тому рабочему, который будет перемещать эти тела. Если же доступны глобальные примитивы взаимодействия (как в библиотеке MPI), возможен другой вариант: рабочие используют их для рассылки и удаления (добавления) значений в векторах сил. После того как все рабочие переместят тела в своих блоках, им нужно обменяться новыми положениями и скоростями тел. Для этого можно использовать сообщения "от точки к точке" или глобальное взаимодействие.
Листинг 11.8 содержит эскиз кода для программы типа "управляющий-рабочие".
Внешний цикл в каждом процессе выполняется один раз на каждом временном шаге имитации. Внутренний цикл в управляющем процессе выполняется numTasks+PR раз, где numTasks — число задач в портфеле. На последних pr итерациях портфель пуст, и управляющий отправляет пару (0, 0) как сигнал о том, что портфель пуст. Получая этот сигнал, каждый из PR процессов выходит из цикла вычисления сил.
Программа пульсации
Аналогом алгоритма с разделяемыми переменными является алгоритм пульсации, использующий передачу сообщений (раздел 9.2); вычислительные фазы в нем чередуются с барьерами. Программа с разделяемыми переменными (см. листинг 11.7) имеет соответствующую структуру, поэтому, чтобы использовать передачу сообщений, программу можно изменить: 1) каждому рабочему процессу назначается подмножество тел; 2) каждый рабочий сначала вычисляет силы в своем подмножестве, а затем обменивается силами с другими рабочими; 3) каждый рабочий перемещает свои тела; 4) рабочие обмениваются новыми положениями и скоростями тел. При имитации эти действия повторяются на каждом шаге по времени.
Назначать тела рабочим процессам можно по любой схеме распределения (см. рис. 11.4): по блокам, полосам или обратным полосам. Распределение по полосам или обратным полосам дает гораздо более сбалансированную вычислительную нагрузку, чем по блокам фиксированного размера. Однако каждому рабочему процессу придется иметь свою собственную копию векторов положений, скоростей, сил и масс. Кроме того, после каждой фазы необходим обмен целыми векторами со всеми остальными рабочими. Все это приводит к большому числу длинных сообщений.
Если рабочим назначать блоки тел, то будет использоваться приблизительно вдвое меньше сообщений, причем они будут короче. (Рабочим процессам также нужно меньше локальной памяти.) Чтобы понять, почему так происходит, рассмотрим пример из предыдущего раздела, в котором четыре процесса и десять задач. При назначении по блокам процесс 1 обрабатывает первые четыре задачи: (1, 1), (1, 2), (1, 3) и (1, 4).
Он вычисляет все силы, связанные с телами блока 1. Для этого ему необходимы положения и скорости тел из блоков 2, 3 и 4, и в эти же блоки ему нужно возвратить силы. Однако процесс 1 никогда не передает другим процессам положения и скорости своих тел, и ему не нужна информация о силах от любого другого процесса. С другой стороны, процесс 4 отвечает только за задачу (4,4). Ему не нужны положения или скорости остальных тел, и он не должен отправлять силы остальным рабочим.
Если все блоки одного размера, то рабочая нагрузка оказывается несбалансированной; затраты времени при этом могут даже превысить выигрыш от отправки меньшего числа сообщений. Но нет и причин, по которым все блоки должны быть одного размера, как в программе с разделяемыми переменными. Более того, тела можно переместить за линейное время, поэтому использование блоков разных размеров приведет к относительно небольшому дисбалансу нагрузки в фазе перемещения тел.
В листинге 11.9 представлена схема кода для программы пульсации, в которой рабочим процессам назначаются блоки разных размеров. Как показано, части кода, связанные с передачей сообщений, не симметричны. Разные рабочие отправляют неодинаковое число сообщений в различные моменты времени. Однако этот недостаток превращен в преимущество с помощью совмещения взаимодействий и вычислений во времени. Каждый рабочий процесс отправляет сообщения и затем до получения и обработки сообщений выполняет локальные вычисления.
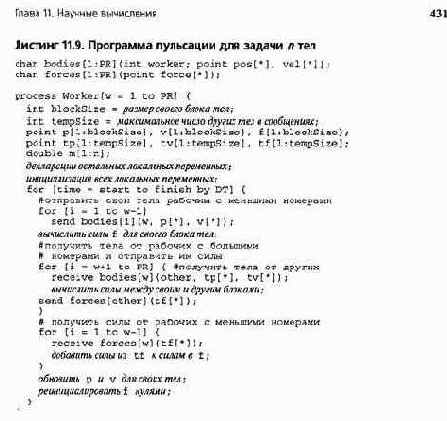
Программа с конвейером
Рассмотрим решение задачи п тел с помощью конвейерного алгоритма (раздел 9.3). Напомним, что в конвейере информация двигается в одном направлении от процесса к процессу. Конвейер бывает открытым, круговым и замкнутым (см. рис. 9.1). Здесь нужна информация о телах, циркулирующая между рабочими процессами, поэтому следует использовать или круговой, или замкнутый конвейер. Управляющий процесс не нужен (за исключением, возможно, лишь инициализации рабочих процессов и сбора конечных результатов), поэтому достаточно кругового конвейера.
Рассмотрим идею использования кругового конвейера. Предположим, что каждому рабочему процессу назначен блок тел и каждый рабочий вычисляет силы, действующие только на тела в своем блоке. (Таким образом, сейчас выполняются лишние вычисления; позже мы используем симметрию сил между телами.) Каждому рабочему для вычисления сил, создаваемых "чужими" телами, нужна информация о них. Таким образом, достаточно, чтобы блоки тел циркулировали между рабочими процессами. Это можно сделать следующим образом..
Отправить р и v своего блока тел следующему рабочему процессу; вычислить силы, действующие между телами своего блока; for [i = 1 to PR-1] {
получить р и v блока тел от предыдущего рабочего процесса;
отправить этот блок тел следующему рабочему процессу;
432 Часть 3. Синхронное параллельное программирование
вычислить силы, с которыми тела нового блока действуют на тела своего блока -, }
получить обратно свой блок тел; переместить тела; реинициализировать силы, действующие на свои тела, нулями;
Каждый рабочий процесс выполняет данный код на каждом временном шаге имитации. (Последняя отправка и получение не обязательны в приведенном коде, однако они понадобятся позже.)
При описанном подходе выполняется вдвое больше вычислений сил, чем необходимо. Следовательно, нам желательно рассматривать каждую пару тел только один раз и пропускать силы, уже вычисленные для какой-либо группы тел. Чтобы сбалансировать вычислительную нагрузку, нужно или назначать разные количества тел каждому процессу (как в программе пульсации), или назначать тела по полосам или обратным полосам, как в программе с разделяемыми переменными. Применим одну из схем назначения тел по полосам, которая даст наиболее сбалансированную нагрузку.
В листинге 11.10 приведен код кругового конвейера, использующий схему присваивания тел по полосам. Каждое сообщение содержит положения, скорости и силы, уже вычисленные для подмножества тел.
В коде не показаны все подробности учета, необходимые, чтобы точно отслеживать, какие тела принадлежат каждому подмножеству; однако это можно определить по идентификатору владельца подмножества. Каждое подмножество тел циркулирует по конвейеру, пока не вернется к своему владельцу, который затем переместит эти тела.

Сравнение программ
Приведенные три программы с передачей сообщений отличаются друг от друга по нескольким параметрам: легкость программирования, сбалансированность нагрузки, число сообщений и объем локальных данных. Легкость программирования субъективна; она зависит от того, насколько программист знаком с каждым из стилей. Тем не менее, если сравнить длину и сложность программ, простейшей окажется программа с конвейером. Она короче
Глава 11. Научные вычисления 433
других, отчасти потому, что в ней используется наиболее регулярная схема взаимодействия. Программа типа "управляющий-рабочие" также весьма проста, хотя ей нужен дополнительный процесс. Программа пульсации сложнее других (хотя и не намного), поскольку в ней используются блоки тел разных размеров и асимметричная схема взаимодействия.
Рабочая нагрузка у всех трех программ будет достаточно сбалансированной. Программа типа "управляющий-рабочие" динамически распределяет работу, поэтому нагрузка здесь почти сбалансирована, даже если процессоры имеют разные скорости или некоторые из них одновременно выполняют другие программы. При выполнении на специализированной однородной архитектуре у конвейерной программы с назначением по полосам рабочая нагрузка будет сбалансирована достаточно, а с назначением по обратным полосам— почти идеально. Программа пульсации использует блоки разных размеров, поэтому нагрузка окажется не идеально, но все-таки почти сбалансированной; кроме того, асимметричная схема взаимодействия и перекрытие взаимодействия и вычислений во времени отчасти скроет несбалансированность вычисления сил.
Во всех программах на каждом шаге по времени отправляются (и получаются) 0(PR2) сообщений. Однако действительные количества сообщений отличаются, как и их размеры (табл. 11.1). Алгоритм пульсации дает наименьшее число сообщений. Конвейер — на PR сообщений больше, но они самые короткие. Больше всего сообщений в программе типа "управляющий-рабочие", однако здесь обмен значениями между рабочими процессами можно реализовать с помощью операций группового взаимодействия.

Наконец, программы отличаются объемом локальной памяти каждого рабочего процесса. В программе типа "управляющий-рабочие" каждый рабочий процесс имеет копию данных о всех телах; ему также нужна временная память для сообщений, число которых может достигать 2п. В программе пульсации каждому процессу нужна память для своего подмножества тел и временная память для наибольшего из блоков, которые он может получить от других. В конвейерной программе каждому рабочему процессу нужна память для своего подмножества тел и рабочая память для еще одного подмножества, размер которого — n/PR. Следовательно, конвейерной программе нужно меньше всего памяти на один рабочий процесс.
Подведем итог: для задачи п тел наиболее привлекательной выглядит программа с конвейером. Она сравнительно легко пишется, дает почти сбалансированную нагрузку, требует наименьшего объема локальной памяти и почти минимального числа сообщений. Кроме того, конвейерная программа будет эффективнее работать на некоторых типах коммуникационных сетей, поскольку каждый рабочий процесс взаимодействует только с двумя соседями. Однако различия между программами относительно невелики, поэтому приемлема любая из них. Оставим читателю интересную задачу реализации всех трех программ и экспериментального сравнения их производительности.
434 Часть 3. Синхронное параллельное программирование
11.2.4. Приближенные методы
В задаче п тел доминируют вычисления сил.
В реальных приложениях для очень больших значений и на вычисление сил приходится более 95 процентов всего времени. Поскольку каждое тело взаимодействует со всеми остальными, на каждом шаге по времени выполняется О(пг) вычислений сил. Однако величина гравитационной силы между двумя телами обратно пропорциональна квадрату расстояния между ними. Поэтому, если два тела находятся далеко друг от друга, то силой их притяжения можно пренебречь.
Рассмотрим конкретный пример: на движение Земли влияют другие тела Солнечной системы, в большей степени Солнце и Луна и в меньшей — остальные планеты. Гравитационная сила воздействия на Солнечную систему со стороны других тел пренебрежимо мала, но оказывается достаточно большой, чтобы вызвать движение Солнечной системы по галактике Млечного пути.
Ньютон доказал, что группу тел можно рассматривать как одно тело по отношению к другим, удаленным, телам. Например, группу тел В можно заменить одним телом Ь, которое имеет массу, равную сумме масс всех тел в В, и расположено в центре масс В. Тогда силу между отдаленным телом /' и всеми телами В можно заменить силой между / и Ь.
Ньютоновский подход приводит к приближенным методам имитации п тел. Первым распространенным методом был алгоритм Барнса—Хата (Barnes—Hut), но теперь чаще используется более эффективный быстрый метод мулыпиполей. Оба метода являются примерами так называемых древесных кодов, поскольку лежащая в их основе структура данных представляет собой дерево тел. Время работы алгоритма Барнса—Хата равно О(п \ogri); для однородных распределений тел время работы быстрого метода мультиполей равно О(п). Ниже кратко описана работа этих методов. Подробности можно найти в работах, указанных в исторической справке в конце данной главы.
Основой иерархических методов является древовидное представление физического пространства. Корень дерева представляет клетку, которая содержит все тела. Дерево строится рекурсивно с помощью разбиения клеток. В двухмерном варианте сначала корневую клетку делят на четыре одинаковые клетки, а затем дробят полученные клетки.
Клетка делится, если количество тел в ней больше некоторого фиксированного числа. Полученное таким образом дерево называется деревом квадрантов (quadtree), поскольку у каждого нелистового узла по четыре сына. Форма дерева соответствует распределению тел, поскольку дерево имеет больше уровней в тех областях, где больше тел. (В трехмерном пространстве родительские клетки делятся на восемь меньших, и структура данных называется деревом октантов.)
На рис. 11.5 проиллюстрирован процесс деления двухмерного пространства на клетки и соответствующее дерево квадрантов. Каждая группа из четырех клеток одинакового размера нумеруется по часовой стрелке, начиная с верхней левой и заканчивая нижней левой, 'и представлена деревом в том же порядке. Каждый узел-лист представляет клетку либо пустую, либо с одним телом.
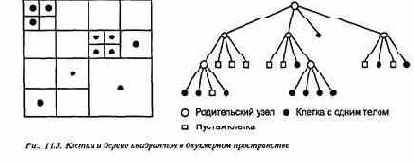
Глава 11. Научные вычисления 435
Алгоритм Барнса—Хата
Алгоритм сложности я'на каждом шаге по времени имеет две фазы вычислений — вычисление сил и перемещение тел. В алгоритме Барнса—Хата есть еще две фазы предварительной обработки. Таким образом, на каждом временном шаге вычисления проводятся в четыре этапа.
1. Строится дерево квадрантов, представляющее текущее распределение тел.
2. Вычисляется полная масса и центр масс каждой клетки. Полученные значения записываются в соответствующем узле дерева квадрантов. Это делается с помощью прохода от листовых узлов к корню.
3. С использованием дерева вычисляются силы, связанные с каждым телом. Начиная с корня дерева, для каждого посещаемого узла рекурсивно выполняют следующую проверку. Если центр масс клетки "достаточно удален" от тела, то клеткой аппроксимируется все соответствующее ей поддерево; иначе обходятся все четыре подклетки. Чтобы определить, "достаточно ли удалена" клетка, используется параметр, заданный пользователем.
4. Тела перемещаются, как и раньше.
На каждом временном шаге дерево перестраивается, поскольку тела перемещаются, и, следовательно, их распределение изменяется.
Однако перемещения, в основном, малы, поэтому дерево можно перестраивать, если только какое-нибудь тело перемещается за пределы своей клетки. В любом случае центры масс всех клеток нужно пересчитывать на каждом временном шаге.
Число узлов в дереве квадрантов равно О(п log//), поэтому фазы 1 и 2 имеют такую же временную сложность. Вычисление сил также имеет сложность О(п logn), поскольку в дереве обходятся только клетки, расположенные близко к телу. Перемещение тел является, как обычно, самой быстрой фазой с временной сложностью О(п).
В алгоритме Барнса—Хата не учитывается свойство симметрии сил между телами, т.е. в фазе вычисления сил каждое тело рассматривается отдельно. (Учет получится слишком громоздким, если пытаться отслеживать все уже вычисленные пары тел.) Тем не менее алгоритм эффективен, поскольку его временная сложность меньше О(п2).
Алгоритм Барнса—Хата сложнее эффективно распараллелить, чем основной алгоритм, из-за следующих дополнительных проблем: 1) пространственное распределение тел в общем случае неоднородно, и, соответственно, дерево не сбалансировано; 2) дерево приходится обновлять на каждом временном шаге, поскольку тела перемещаются; 3) дерево является связанной структурой данных, которую гораздо сложнее распределить (и использовать), чем простые массивы. Эти проблемы затрудняют балансировку рабочей нагрузки и ослабление требований памяти. Например, процессорам нужно было бы назначить поровну тел, но это не будет соответствовать каким бы то ни было регулярным разбиениям пространства на клетки. Более того, процессорам нужно работать вместе, чтобы построить дерево, и при вычислении сил им может понадобиться все дерево. В результате многолетних исследований по имитации задачи п тел были разработаны эффективные методы ее параллельной реализации (см. историческую справку в конце главы). В настоящее время можно имитировать эволюцию систем, содержащих сотни миллионов тел, и на тысячах процессоров получать существенное ускорение.
Быстрый метод мультиполей
Быстрый метод мультиполей (Fast Multipole Method — FMM) является усовершенствованием метода Барнса-Хата и требует намного меньше вычислений сил. Метод Барнса-Хата рассматривает только взаимодействия типа тело-тело и тело-клетка. В FMM также вычисляются взаимодействия типа клетка-клетка. Если внутренняя клетка дерева квадрантов находится достаточно далеко от другой внутренней клетки, то в FMM вычисляются силы между двумя клетками, и полученный результат переносится на всех потомков обеих клеток.
Второе основное отличие FMM от метода Барнса-Хата состоит в способе, по которому методы управляют точностью аппроксимации сил. Метод Барнса-Хата представляет каждую клетку точкой, размещенной в центре масс клетки, и для аппроксимации силы учитывает
436 Часть 3. Синхронное параллельное программирование
расстояние между телом и данной точкой. В FMM распределение массы в клетке представляется с помощью ряда разложений и считается, что две клетки достаточно удалены друг от друга, если расстояние между ними намного превосходит длину большей из их сторон. Таким образом, аппроксимации в FMM используются намного чаще, чем в методе Барнса—Хата, но это компенсируется более точным описанием распределения массы внутри клетки.
Фазы на временном шаге в FMM такие же, как и в методе Барнса—Хата, но фазы 2 и 3 реализуются иначе. Благодаря вычислению взаимодействий типа клетка-клетка и аппроксимации гораздо большего числа сил, временная сложность FMM равна О(п) для однородных распределений тел в пространстве. FMM трудно распараллелить, но применение такой же техники, как в методе Барнса—Хата, все-таки позволяет сделать это достаточно эффективно.
