Новые решения задачи о читателях и писателях
С применением нотации совместно используемых примитивов можно программировать фильтры и взаимодействующие равные так же, как в главе 7. Поскольку эта нотация включает и RPC, и рандеву, можно программировать процессы-клиенты и процессы-серверы, как в разделах 8.1 и 8.2. Совместно используемые примитивы обеспечивают дополнительную гибкость, которая демонстрируется здесь. Сначала разработаем еще одно решение задачи о читателях и писателях (см. раздел 4.4). В отличие от предыдущих решений, здесь инкапсулирован доступ к базе данных. Затем расширим решение до распределенной реализации дублируемых файлов или баз данных. Обсудим также, как можно программировать эти решения, используя только RPC и локальную синхронизацию или только рандеву.
8.4.1. Инкапсулированный доступ
Напомним, что в задаче о читателях и писателях читательские процессы просматривают базу данных, возможно, параллельно. Процессы-писатели могут изменять базу данных, поэтому им нужен исключающий доступ к базе данных. В предыдущих решениях (с помощью семафоров в листингах 4.9 и 4.12 или с помощью мониторов в листинге 5.4) база данных была глобальной по отношению к процессам читателей и писателей, чтобы читатели могли обращаться к ней параллельно. При этом процессы должны были перед доступом к базе данных запрашивать разрешение, а после работы с ней освобождать доступ. Намного лучше инкапсулировать доступ к базе данных в модуле, чтобы спрятать протоколы запроса и освобождения, тем самым гарантируя их выполнение. Такой подход поддерживается в языке Java (это показано в конце раздела 5.4), поскольку программист может выбирать, будут методы (экспортируемые операции) выполняться параллельно или по одному. При использовании составной нотации решение можно структурировать аналогичным образом, причем полученное решение будет еще короче, а синхронизация — яснее.
302 Часть 2. Распределенное программирование
В листинге 8. 13 представлен модуль, инкапсулирующий доступ к базе данных. Клиентские процессы просто вызывают операции read или write, а вся синхронизация скрыта внутри модуля. В реализации модуля использованы и RPC, и рандеву. Операция read реализована в виде ргос, поэтому несколько процессов-читателей могут выполняться параллельно, но операция write реализована на основе рандеву с процессом Writer, поэтому операции записи обслуживаются по очереди. Модуль также содержит две локальные операции, star tread и endread, которые используются, чтобы обеспечить взаимное исключение операций чтения и записи. Их также обслуживает процесс Writer, поэтому он может отслеживать количество активных процессов-читателей и при необходимости откладывать выполнение операции write. Благодаря использованию рандеву в процессе Writer ограничения синхронизации выражаются непосредственно в виде логических условий, без обращений к условным переменным или семафорам. Отметим, что локальная операция endread вызывается оператором send, а не call, поскольку процесс-читатель не обязан ждать завершения обслуживания endread.

В языке, поддерживающем RPC, но не рандеву, этот модуль пришлось бы запрограммировать иначе. Например, обе операции read и write должны быть реализованы как экспортируемые процедуры, которые в свою очередь должны вызывать локальные процедуры для запроса разрешения на доступ к базе данных и для освобождения доступа. Внутренняя синхронизация должна обеспечиваться семафорами или мониторами.
Хуже, если язык поддерживает только рандеву. Операции обслуживаются существующими процессами, и каждый процесс может обслуживать одновременно только одну операцию. Таким образом, есть только один способ обеспечить параллельное чтение базы данных — экспортировать массив операций чтения, по одной для каждого клиента, и для их обслуживания использовать отдельные процессы. Такое решение по меньшей мере неуклюже и неэффективно.
Решение в листинге 8.13 отдает предпочтение читателям.
Приоритет писателям можно дать, изменив оператор ввода с помощью функции ? для приостановки вызовов операции startread, когда есть задержанные вызовы операции write.

газраоотка решения со справедливым планированием оставляется читателю.
Модуль в листинге 8.13 блокирует для читателей или для писателей всю базу данных. Обычно этого достаточно для небольших файлов данных. Однако для транзакций в базах данных обычно нужно блокировать отдельные записи по мере их обработки, поскольку заранее не известно, какие конкретно записи понадобятся в транзакции. Например, транзакции нужно просмотреть некоторые записи, чтобы определить, какие именно считывать далее. Для реализации такого вида динамической блокировки можно использовать много модулей, по одному на каждую запись. Но тогда не будет инкапсулирован доступ к базе данных. Вместо этого в модуле ReadersWriters можно применить более сложную схему блокировки с мелкомодульной структурой. Например, выделять необходимые блокировки для каждой операции read и write. Именно этот подход типичен для систем управления базами данных.
8.4.2. Дублируемые файлы
Простой способ повысить доступность файла с критическими данными — хранить его резервную копию на другом диске, обычно расположенном на другой машине. Пользователь может делать это вручную, периодически копируя файлы, либо файловая система будет автоматически поддерживать копию таких файлов. В любом случае при необходимости доступа к файлу пользователь должен сначала проверить доступность основной копии файла и, если она недоступна, использовать резервную копию. (С этой задачей связана проблема обновления основной копии, когда она вновь становится доступной.)
Третий подход состоит в том, что файловая система обеспечивает прозрачное копирование. Предположим, что есть п копий файла данных и n серверных модулей. Каждый сервер обеспечивает доступ к одной копии файла. Клиент взаимодействует с одним из серверных модулей, например, с тем, который выполняется на одном процессоре с клиентом.
Серверы взаимодействуют между собой, создавая у клиентов иллюзию работы с файлом. На рис. 8.1 показана структура такой схемы взаимодействия.
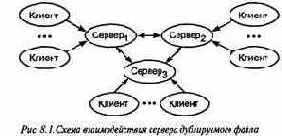
Каждый модуль сервера экспортирует четыре операции: open, close, read и write. Желая обратиться к файлу, клиент вызывает операцию open своего сервера с указанием, собирается он записывать в файл или читать из него. Затем клиент общается с тем же сервером, вызывая операции read и write. Если файл был открыт для чтения, можно использовать только операции read, а если для записи — и read, и write. В конце концов клиент заканчивает диалог, вызвав операцию close. (Эта схема взаимодействия совпадает с приведенной в конце раздела 7.3.)
Файловые серверы взаимодействуют, чтобы поддерживать согласованность копий файла и не давать делать записи в файл одновременно нескольким процессам. В каждом файловом
304 , Часть 2. Распределенное программирование
сервере есть локальный процесс-диспетчер блокировок, реализующий решение задачи о читателях и писателях. Когда клиент открывает файл для чтения, операция open вызывает операцию s tar tread локального диспетчера блокировок. Но когда клиентский процесс открывает файл для записи, операция open вызывает startwrite для всех n диспетчеров блокировок.
В листинге 8.14 представлен модуль FileServer. Для простоты использован массив и статическое именование, хотя на практике серверы должны создаваться динамически и размещаться на разных процессорах. Так или иначе, в реализации этого модуля есть несколько интересных аспектов.


• каждый модуль Fiieserver экспортирует два наоора операции: вызываемые его клиентами и вызываемые другими файловыми серверами. Операции open, close, read и write реализованы процедурами, но read— единственная, которая должна быть реализована процедурой, чтобы допустить параллельное чтение. Операции блокировки реализованы с помощью рандеву с диспетчером блокировок.
• Каждый модуль следит за текущим режимом доступа (каким образом файл был открыт последний раз), чтобы не разрешать записывать в файл, открытый для чтения, и определять, какие действия нужно выполнить при закрытии файла.
Но модуль не защищен от клиента, получившего доступ к файлу, предварительно не открыв его. Эту проблему можно решить с помощью динамического именования или дополнительных проверок в других операциях.
• В процедуре write модуль сначала обновляет свою локальную копию файла, а затем параллельно обновляет все удаленные копии. Это аналогично использованию стратегии сквозного обновления кэш-памяти. Вместо этого можно использовать стратегию с обратной записью, при которой операция write обновляет только локальную копию, а удаленные копии файла обновляются при его закрытии.
• В операции open клиент получает блокировки записи, по одной от каждого блокирующего процесса. Чтобы не возникла взаимоблокировка клиентов, все клиенты получают блокировку в одном и том же порядке. В операции close клиент освобождает блокировки записи с помощью оператора send, а не call, поскольку процессу не нужно ждать освобождения блокировок.
• Диспетчер блокировок реализует решение задачи о читателях и писателях с классическим предпочтением для читателей. Это активный монитор, поэтому инвариант его цикла тот же, что инвариант монитора в листинге 5.4.
В программе в листинге 8.14 читатель для чтения файла должен получить только одну блокировку чтения. Писатель же должен получить все n блокировок записи, по одной от каждого экземпляра модуля FileServer. В обобщении этой схемы нужно использовать так называемое взвешенное голосование.
Пусть readWeight — это число блокировок, необходимых для чтения файла, awriteWeight — для записи в файл. В нашем примере readWeight равно 1, awriteWeight — п. Можно было бы использовать другие значения — для readWeight значение 2, а для writeWeight — n-2. Это означало бы, что читатель должен получить две блокировки чтения и п-2 блокировок записи. Можно использовать любые весовые значения, лишь бы выполнялись следующие условия.
writeWeight > n/2 и (readWeight + writeWeight) > n
306 Часть 2.Распределенное программирование
При использовании взвешенного голосования, когда писатель закрывает файл, нужно обновить только копии, заблокированные для записи. Но каждая копия должна иметь метку времени последней записи в файл. Первое указанное выше требование гарантирует, что самые свежие данные и последние метки времени будут по меньшей мере у половины копий. (Как реализовать глобальные часы и метки времени последнего доступа к файлам, описывается в разделе 9.4.)
Открывая файл и получая блокировки чтения, читатель также должен прочитать метки времени последних изменений в каждой копии файла и использовать копию с самой последней меткой. Второе из указанных выше требований гарантирует, что будет хотя бы одна копия с самым последним временем изменений и, следовательно, с самыми последними данными. В нашей программе в листинге 8.14 не нужно было заботиться о метках времени, поскольку при закрытии файла обновлялись все его копии.