Языки и модели
Большинство эффективных параллельных программ написаны с помощью последовательного языка (как правило, С или Фортран) и библиотеки. Для этого есть несколько причин. Во-первых, программисты хорошо знают какой-нибудь последовательный язык и имеют опыт написания научных программ. Во-вторых, библиотеки совместимы с обычно используемыми параллельными вычислительными платформами. В-третьих, высокая производительность — основная цель быстродействующих вычислений, а библиотеки создаются под конкретное аппаратное обеспечение, предоставляя программисту управление на низком уровне.
Однако использование языка высокого уровня, содержащего механизмы как последовательного, так и параллельного программирования, тоже имеет ряд преимуществ. Во-первых, язык обеспечивает более высокий уровень абстракции, что может помочь программисту ориентироваться в решении задачи. Во-вторых, последовательные и параллельные механизмы можно объединять, чтобы они работали вместе, а аналогичные алгоритмы имели сходное выражение. Эти два свойства облегчают создание и понимание программ (как правило, относительно коротких). В-третьих, язык высокого уровня обеспечивает контроль типов, освобождая программиста от необходимости проверять соответствие типов данных (об этом можно даже и не вспоминать). Это оберегает программиста от многих ошибок, позволяет создавать более короткие и устойчивые программы. Основные проблемы разработчиков языка — разработать хороший набор абстракций, мощный и ясный набор механизмов, а также эффективную реализацию.
Для параллельного программирования разработаны различные языки. На рис. 12.3 перечислены языки, которые часто используются или воплощают важные идеи. Языки на рисунке сгруппированы в классы в соответствии с лежащей в их основе моделью программирования: разделяемые переменные, передача сообщений, координация, параллельность по данным и функциональность. Языки первых трех классов используются для создания императивных программ, в которых процессы, взаимодействие и синхронизация программируются явно.
Языки с параллельно стью по данным имеют неявную синхронизацию, а функциональные — неявные параллельность и синхронизацию. Последняя группа языков на рис. 12.3 содержит три абстрактные модели, которые можно использовать для сравнения алгоритмов и оценки производительности.
Некоторые языки, перечисленные на рис. 12.3, были описаны в предыдущих главах книги. В данном разделе представлен краткий обзор новых, не рассмотренных до сих пор, аспектов языков и моделей и дается более подробное описание быстродействующего Фортрана (HPF). В исторической справке в конце главы содержатся ссылки на источники дальнейшей информации по конкретным языкам, а также описываются книги и обзорные статьи, дающие общее представление о языках и моделях.
12.3.1. Императивные языки
Языки первых трех классов на рис. 12.3 используются для создания императивных программ, в которых явно обновляется и синхронизируется доступ к состоянию программы, т.е. к значениям переменных. Все эти языки имеют средства для определения процессов, задач или потоков, которые отличаются способом программирования взаимодействия и синхронизации. По первому способу для взаимодействия применяются разделяемые переменные, а для синхронизации— разделяемые блокировки, флаги, семафоры или мониторы. По второму — и для взаимодействия, и для синхронизации используются сообщения. Некоторые языки поддерживают один из этих способов, некоторые — оба, предоставляя программисту выбор в зависимости от решаемой задачи или архитектуры машины, на которой будет работать программа. Третий способ заключается в обеспечении области разделяемых данных и операций над ними, подобных сообщениям (см. обсуждение языков с координацией ниже).
Учебные примеры многих языков, поддерживающих явное параллельное программирование, уже рассматривались. Три из них (Ada, Java и SR) на рис. 12.3 указаны дважды, по-

468 Часть 3. Синхронное параллельное программирование
Cilk
Язык Cilk расширяет С пятью простыми механизмами для параллельного программирования. Cilk хорошо подходит для рекурсивного параллелизма, хотя также поддерживает параллельность по задачам и по данным. Cilk разрабатывался для эффективного выполнения на симметричных мультипроцессорах с разделяемой памятью.
Новшеством в Cilk является то, что если из Cilk-программы убрать специфические для Cilk конструкции, то оставшийся код будет синтаксически и семантически корректной С-программой. Пять механизмов Cilk обозначаются ключевыми словами cilk, spawn, synch, inlet и abort. Ключевое слово с ilk добавляется в начало декларации С-функции и указывает, что функция является Cilk-процедурой. В такой процедуре при выполнении оператора spawn происходит разделение процессов. Порожденные потоки выполняются параллельно с родительским, вызывающим потоком. Для ожидания, пока все порожденные потоки завершат вычисления и возвратят результаты, в родительском потоке используется оператор synch. Таким образом, последовательность операторов spawn, за которой следует оператор synch, в сущности, является оператором со/ос.
Следующий пример иллюстрирует реализацию (неэффективную) рекурсивной параллельной программы для вычисления n-го числа Фибоначчи.

Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 469
Последний механизм Cilk, abort, используется внутри входов; он уничтожает потоки, порожденные одним и тем же родителем, которые еще выполняются. Одним из применений механизма abort может служить программа рекурсивного поиска, в которой многие пути исследуются параллельно; программист может уничтожить поток, исследующий путь, если уже найдено лучшее решение.
Новизной реализации Cilk является так называемый диспетчер захвата работы. Cilk реализует две версии каждой Cilk-процедуры: быстрая, работающая, как обычная С-функция, и медленная, которая полностью поддерживает параллельность со всеми сопутствующими накладными расходами.
При порождении процедуры выполняется быстрая версия. Если некоторому рабочему процессу (который выполняет Cilk-потоки) нужна работа, он захватывает процедуру от какого-либо другого рабочего процесса. В этот момент процедура преобразуется в медленную версию.
Фортран М
Этот язык является небольшим набором расширений Фортрана, поддерживающим модульную разработку программ с обменом сообщениями. Механизмы обмена сообщениями аналогичны механизмам, описанным в главе 7. Хотя этот язык больше не поддерживается, его возможности включены в MPI-связывание для языка HPF.
Процесс в Фортране М похож на процедуру с параметрами, но имеет ключевое слово process вместо procedure. Оператор processcall используется для создания нового процесса. Такие вызовы встречаются в частях программы, отмеченных операторами ргос-esses/endprocesses, которые подобны оператору со/ос.
Процессы в Фортране М взаимодействуют друг с другом с помощью портов и каналов; они не могут разделять переменные. Канал представляет собой очередь сообщений. Он создается с помощью оператора channel, который определяет пару портов— вывода и ввода. Оператор send добавляет сообщение в порт вывода. Оператор endchannel добавляет в порт вывода сообщение, отмечающее конец канала. Оба оператора являются неблокирующими (асинхронными). Оператор receive ожидает сообщения в порту ввода, затем удаляет сообщение (таким образом, receive является блокирующим).
Каналы можно создавать и уничтожать динамически, передавать в качестве аргументов процессам и отправлять в сообщениях как значения. Например, чтобы позволить двум процессам взаимодействовать друг с другом, программисту сначала нужно создать два канала, затем — два процесса и передать им каналы как аргументы. Первый процесс использует порт вывода одного канала и порт ввода другого; второй — другие порты этих двух каналов.
Фортран М главным образом предназначен для программирования параллельности по задачам, в котором процессы выполняют, вообще говоря, разные задачи.
Однако с помощью распределенных массивов язык поддерживает и программирование, параллельное по данным. Операторы распределения данных похожи на операторы, поддерживаемые HPF, который обсуждается в конце раздела 12.3.
12.3.2. Языки с координацией
Язык с координацией является расширением какого-либо основного языка с разделяемой областью данных и примитивами, подобными сообщениям, для обработки области данных. Идея таких языков происходит от набора примитивов Linda (раздел 7.7). Напомним, что Linda расширяет основной язык, например С, с помощью абстракции ассоциативной памяти, называемой пространством кортежей (ПК). ПК концептуально разделяется всеми процессами. Новый кортеж помещается в ПК при выполнении примитива out, извлекается оттуда с помощью in и проверяется при выполнении rd. Наконец, с помощью примитива eval процессы создаются; завершая работу, процесс помещает возвращаемое им значение в ПК. Таким образом, в Linda комбинируются аспекты разделяемых переменных и асинхронного обмена сообщениями — пространство кортежей разделяется всеми процессами, кортежи помещаются и извлекаются неделимым образом, как будто они — сообщения.
470 Часть 3. Синхронное параллельное программирование
Огса
Это более современный пример языка с координацией. Подобно Linda, он основан на структурах данных, которые концептуально разделяются, хотя физически могут быть распределенными. Объединяющим понятием в Огса является не разделяемый кортеж, а разделяемый объект данных. Процессы на разных процессорах могут совместно использовать пассивные объекты — экземпляры абстрактных типов. Процессы получают доступ к разделяемому объекту, вызывая операцию, которая определена объектом. Операции реализуются с помощью механизма, сочетающего аспекты RPC и рандеву.
С помощью примитива fork процесс в Огса создает еще один процесс. Параметры процесса могут быть значениями (value) или разделяемыми (shared).
Для параметра- значения родительский процесс создает копию аргумента и передает ее процессу-сыну. Для разделяемого параметра аргумент должен быть переменной, которая является объектом типа, определяемого пользователем. После создания процесса-сына он и родитель разделяют этот объект.
Каждый определенный пользователем тип описывает операции над объектами этого типа. Каждый экземпляр разделяемого объекта является монитором или серверным процессом, в зависимости от реализации. В обоих случаях операции над объектом выполняются неделимым образом. Реализация операции в Огса может состоять из одного или нескольких защищенных операторов. В Огса поддерживается синхронизация условий с помощью булевых выражений, а не условных переменных.
В первоначальной версии Огса поддерживалась только параллельность по задачам, в современной — также и по данным. Это реализовано с помощью разбиения на части объектов данных, основанных на массивах, распределения этих частей по разным процессорам и их обработки с использованием параллельных операций, определенных пользователем.
12.3.3. Языки с параллельностью по данным
Языки с параллельностью по данным непосредственно поддерживают стиль программирования, в котором все процессы выполняют одни и те же операции на разных частях разделяемых данных. Таким образом, языки с параллельностью по данным являются императивными. Однако, несмотря на явное взаимодействие в этих языках, синхронизация выражается неявно — после каждого оператора есть неявный барьер.
Понятие параллельность по данным появилось в середине 1980-х с появлением первой Connection Machine, CM-1, с архитектурой типа SIMD.29
СМ-1 состояла из обычного управляющего процессора и специального мультипроцессора, состоявшего из тысяч небольших (серверных) процессоров. Управляющий процессор выполнял последовательные команды и рассылал параллельные команды всем серверным.процессорам; там эти команды выполнялись синхронно.
Чтобы упростить программирование СМ-1, сотрудники корпорации Thinking Machines разработали язык С* (С Star) — вариант языка С, параллельный по данным.
И хотя SIMD-машины, подобные СМ-1, больше не производятся, стиль программирования, параллельного по данным, остался, поскольку многие приложения легче всего программируются именно в этом стиле. Ниже мы дадим обзор основных черт языков С* и ZPL — нового интересного языка. В следующем разделе описан NESL — еще один новый язык, параллельный по данным и функциональный. Затем представлен учебный пример по HPF, наиболее широко используемому языку с параллельностью по данным. Поскольку в этих языках синхронизация (в основном) неявна, их компиляторы генерируют код, необходимый для синхронизации. Таким образом, не программист, а компилятор использует базовую библиотеку.
с*
Структура языка С* тесно связана с архитектурой СМ-1. Он дополняет С свойствами, позволяющими выражать топологию данных и параллельные вычисления. Например, в С* есть
29 Сам стиль архитектуры SIMD появился гораздо раньше — в 1960-х.
Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 471
конструкция shape для задания формы параллельных структур данных, например матриц. Параллельное выполнение задается с помощью оператора wi th, который состоит из последовательности операторов, параллельно обрабатывающих данные. Оператор where поддерживает условное выполнение параллельных операторов. С* также определяет количество операторов редукции, которые комбинируют значения неделимым образом. Рассмотрим следующий несложный фрагмент программы.

В первой строке определяется квадратная форма (shape) с именем grid, во второй — две матрицы действительных чисел, имеющие эту форму. В теле оператора with матрица Ь копируется в а, затем следуют оператор where и оператор редукции для накопления суммы всех положительных элементов матрицы а. Оба операторы присваивания внутри оператора where выполняются параллельно по всем элементам а и Ь.
Сопрограмма начинает работу на управляющем процессоре, где выполняются все последовательные операторы. Параллельные операторы компилируются в команды, рассылаемые по одной серверным процессорам.
Connection Machine обеспечивала аппаратную поддержку операторов редукции и параллельного перемещения данных между обрабатывающими элементами.
ZPL
Этот новый язык поддерживает и параллельность по данным, и обработку массивов. Таким образом, выражения вроде А+В обозначают сложение целых массивов, которое может выполняться параллельно и заканчивается неявным барьером. ZPL является законченным языком, а не расширением какого-то базового. Однако он компилируется в ANSI С, согласовывается с кодами на Фортране или С и обеспечивает доступ к научным библиотекам.
Новые аспекты ZPL — области и направления. Вместе с выражениями обработки массивов они значительно упрощают программирование обработки матриц. Для иллюстрации объявления и использования областей и направлений используем метод итераций Якоби. Отметим, насколько проще выглядит программа по сравнению с явно параллельной программой влистинге 11.2 и особенно — с программами на C/Pthreads и C/MPI (см. листинги 12.1 и 12.2).
Область (region) — это просто набор индексов. Направление используется для модификации областей или выражений с индексами массивов. Объявляются они следующим образом.

472 Часть 3. Синхронное параллельное программирование
Префиксы областей указывают на то, что операторы применяются к целым массивам. Таким образом, в первой строке совершается п2
присваиваний. В каждой из остальных четырех строк выполняется п присваиваний и неявно увеличиваются размеры А, чтобы включить граничные векторы (это означает, что память, выделенная для А, в действительности содержит (п+2)2 значений). Каждый оператор может быть реализован параллельно и завершает свою работу до того, как начинает выполняться следующий оператор. Операторы независимы, поэтому после каждого из них барьер не нужен.
Главный цикл для метода итераций Якоби можно записать на ZPL следующим образом. [R] repeat
Temp := ( A@north + Aieast + Aiwest +
A@south ) / 4; error := max« abs (A-Temp) ; A := Temp; until error < EPSILON;
Префикс региона [R] вновь указывает, что операторы в цикле обрабатывают целые массивы. Первый оператор присваивает каждому элементу Temp среднее арифметическое значений четырех его ближайших соседей в А; заметьте, как для выражения индексов этих соседей используются направления. Второй оператор присваивает переменной error максимальное значение разностей пар значений в А и Temp; кодтах« является оператором редукции.
12.3.4. Функциональные языки
В императивных языках процессы, взаимодействие и синхронизация выражаются явно. Языки с параллельностью по данным имеют неявную синхронизацию. В функциональных языках неявно все!
В функциональных языках программирования, по крайней мере "чистых", нет концепции видимого состояния программы и, следовательно, нет оператора присваивания, изменяющего состояние. Их называют языками с одиночным присваиванием, поскольку переменная может быть связана со значением только один раз. Программа записывается как композиция функций из некоторого набора, а не последовательность операторов.
В языках с одиночным присваиванием нет побочных эффектов, поэтому все аргументы в вызове функции могут вычисляться параллельно. Кроме того, вызываемую функцию можно вычислять, как только будут вычислены все ее аргументы. Таким образом, параллельность явно задавать не нужно; она присутствует автоматически. Процессы взаимодействуют неявно с помощью аргументов и возвращаемых значений. Наконец, синхронизация следует непосредственно из семантики вызова и возврата функции — тело функции не может выполняться, пока не будут вычислены ее аргументы, а результат функции не доступен до возврата из функции.
С другой стороны, семантика одиночного присваивания затрудняет эффективную реализацию функциональных программ. Даже если обновляется только один элемент массива, концептуально 1 создается новая копия всего массива, хотя в нем изменилось всего одно значение.
Таким образом, компилятор должен решать, в каких ситуациях безопасно обновлять массив на месте, а не создавать копию. Чтобы определить, перекрываются ли ссылки в массив, нужен анализ зависимости.
Обладая простыми, но мощными свойствами, функциональные языки давно популярны в последовательном программировании. Основанные на функциях, они особенно хороши в рекурсивном программировании. Одним из первых функциональных языков был Lisp; два других языка, Haskell и ML, популярны в настоящее время. В их реализации можно использовать параллельность. В их версиях программисту позволяется решать, где и в какой степени нужна параллельность. Например, Multilisp является версией Lisp, a Concurrent ML — стандартного ML (Standard ML).
Ниже описываются два функциональных языка, NESL и Sisal, разработанные специально для параллельного программирования.
Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 473
NESL
NESL — функциональный язык с параллельностью по данным. Наиболее важными новыми идеями NESL являются: 1) вложенная параллельность по данным и 2) модель производительности, основанная на языке. NESL допускает применение функции параллельно к каждому элементу набора данных и вложенные параллельные вызовы. Модель производительности основана на концепциях работы и глубины, а не на времени работы. Неформально работа в вычислении — это общее число выполняемых операций, а глубина — самая длинная цепочка последовательных зависимостей.
Последовательные аспекты NESL основаны на ML, функциональном языке, и SETL, лаконичном языке программирования со множествами. Для иллюстрации языка рассмотрим функцию, которая реализует алгоритм быстрой сортировки.

Последовательности являются базовым типом данных в NESL, поэтому аргументом функции является последовательность S. Оператор if возвращает S, если длина S не больше 1. В противном случае в теле функции выполняется пять присваиваний: 1) переменной а присваивается случайный элемент S, 2) в последовательность S1 записываются все значения из S, которые меньше а, 3) в S2 — все значения из S, равные а, 4) в S3 — все значения из S больше а и 5) последовательности R присваивается результат рекурсивного вызова функции Quicksort.
В четырех последних операторах присваивания для параллельного вычисления значений используется оператор "применить ко всем" { ... }. Например, выражение в присваивании 51 означает "параллельно найти все элементы е из S, которые меньше а". Выражение в присваивании R означает "параллельно вызвать Quicksort (v) для v, равного SI и v, равного S3"; приведенный код является примером вложенной параллельности по данным. Результатами рекурсивных вызовов являются последовательности. В последней строке к первому результату к [ 0 ] дописываются последовательность S2 и второй результат R [ 1 ].
Sisal
Sisal (Streams and Iteration in a Single Assignment Language — потоки и итерация в языке с одиночным присваиванием) стал первым функциональным языком, разработанным специально для создания научных программ. Его основные понятия — функции, массивы, итерация и потоки. Функции используются, как обычно, для рекурсии и структурирования программы; итерация и массивы — для итеративного параллелизма (они будут рассмотрены ниже). Потоки — это последовательности значений, доступных по порядку; они используются в конвейерном параллелизме и в операциях ввода-вывода. Sisal больше не поддерживается его создателями из лаборатории Lawrence Livermore, однако он внес в программирование важные идеи и используется до сих пор.
Цикл for в языке Sisal является первичным механизмом для выражения итеративного параллелизма. Его можно применять, если итерации независимы. Например, в следующем коде для вычисления матрицы с как произведения матриц айв используются два цикла.

474 Часть 3 Синхронное параллельное программирование
Слово cross указывает, что внешний цикл выполняется параллельно для всех пар (cross-product), или комбинаций, образуемых n значениями i и п значениями j. Тело внешнего цикла образовано еще одним циклом, который возвращает скалярное произведение А [ i, * ] и В [ *, j ]; ключевое слово sum является оператором редукции.
Внешний цикл возвращает массив элементов, вычисленных п2 экземплярами внутреннего цикла. Отметим, что циклы расположены в правых частях двух операторов присваивания; этот синтаксис отражает семантику одиночного присваивания в функциональном языке.
В Sisal поддерживается еще одна циклическая конструкция, for initial. Ее используют, когда есть зависимость, создаваемая циклом. Она позволяет написать императивный цикл в функциональном стиле. Например, следующий цикл создает вектор х[1:п], содержащий все частичные суммы вектора у [ 1:n]. (Эта параллельная префиксная проблема рассматривалась в разделе 3.5.)
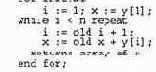
В первой части инициализируются две новые переменные и выполняется первая итерация. В части while к предыдущему значению i каждый раз добавляется 1 и вычисляется новое значение х, которое равно сумме у [ i ] и предыдущего значения х. Данный цикл возвращает массив, содержащий заново вычисленные значения х.
Реализация Sisal основана на модели потоков данных. Выражение можно вычислить, как только будут вычислены его операнды. В цикле умножения матриц, приведенном выше, матрицы А и в даны и зафиксированы, поэтому можно вычислить все произведения. Суммы произведений определяются по мере вычисления произведений. Наконец, массив элементов можно строить по мере того, как вычисляются все скалярные произведения. Таким образом, каждое значение переходит к тем операторам, которым оно нужно, а операторы порождают выходные значения, только получив все свои входные значения. Модель выполнения, основанная на потоках данных, применяется и в вызовах функций: аргументы независимы, поэтому их можно вычислить параллельно, а тело функции — после определения всех аргументов.
12.3.5. Абстрактные модели
Обычно для определения производительности параллельной программы измеряют время ее выполнения или учитывают каждую операцию. Очевидно, что измерения времени выполнения зависят от сгенерированного машинного кода и соответствующего аппаратного обеспечения.
Подсчет операций основан на знании, какие операции можно выполнять параллельно, а какие должны быть выполнены последовательно, и на учете накладных расходов, вносимых синхронизацией. Оба подхода предоставляют подробную информацию, но только относительно одного набора предположений.
Модель параллельных вычислений обеспечивает высокоуровневый подход к характеризации и сравнению времени выполнения различных программ. Это делается с помощью абстракции аппаратного обеспечения и деталей выполнения. Первой важной моделью параллельных вычислений стала машина с параллельным случайным доступом (Parallel Random Access Machine — PRAM). Она обеспечивает абстракцию машины с разделяемой памятью. Модель BSP (Bulk Synchronous Parallel — массовая синхронная параллельная) объединяет абстракции и разделенной, и распределенной памяти. В LogP моделируются машины с распределенной памятью и специальным способом оценивается стоимость сетей и взаимодействия. Упоминавшаяся модель работы и глубины NESL основана на структуре программы и не связана с аппаратным обеспечением, на котором выполняется программа. Ниже дается обзор моделей PRAM, BSP и LogP.
Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 475
PRAM
PRAM является идеализированной моделью синхронной машины с разделяемой памятью. Все процессоры выполняют команды синхронно. Если они выполняют одну и ту же команду, PRAM является абстрактной SIMD-машиной; однако процессоры могут выполнять и разные команды. Основными командами являются считывание из памяти, запись в память и обычные логические и арифметические операции.
Модель PRAM идеализирована в том смысле, что каждый процессор в любой момент времени может иметь доступ к любой ячейке памяти. Например, каждый процессор в PRAM может считывать данные из ячейки памяти или записывать данные в эту же ячейку. Очевидно, что на реальных параллельных машинах такого не бывает, поскольку модули памяти упорядочивают доступ к одной и той же ячейке памяти.
Более того, время доступа к памяти на реальных машинах неоднородно из-за кэшей и возможной иерархической организации модулей памяти.
Базовая модель PRAM поддерживает параллельные считывание и запись (Concurrent Read, Concurrent Write — CRCW). Существуют две более реалистические версии модели PRAM.
• Исключительное считывание, исключительная запись (Exclusive Read, Exclusive Write — EREW). Каждая ячейка памяти в любой момент времени доступна только одному процессору.
• Параллельное считывание, исключительная запись (Concurrent Read, Exclusive Write — CREW). Из каждой ячейки памяти в любой момент времени данные могут считываться параллельно, но записываться только одним процессором.
Эти модели более ограничены и, следовательно, более реалистичны, однако и их нельзя реализовать на практике. Несмотря на это, модель PRAM и ее подмодели полезны для анализа и сравнения параллельных алгоритмов.
BSP х
В модели массового синхронного параллелизма (BSP) синхронизация отделена от взаимодействия и учтены влияние иерархии памяти и обмена сообщениями. Модель BSP состоит из трех компонентов:
• процессоры, которые имеют локальную память и работают с одинаковой скоростью;
• коммуникационная сеть, позволяющая процессорам взаимодействовать друг с другом;
• механизм синхронизации всех процессоров через регулярные отрезки времени.
Параметрами модели являются число процессоров, их скорость, стоимость взаимодействия и период синхронизации.
Вычисление в BSP состоит из последовательности сверхшагов. На каждом отдельном сверхшаге процессор выполняет вычисления, которые обращаются к локальной памяти, и отправляет сообщения другим процессорам. Сообщения являются запросами на получение копии (чтение) или на обновление (запись) удаленных данных. В конце сверхшага процессоры выполняют барьерную синхронизацию и затем обрабатывают запросы, полученные в течение данного сверхшага. Далее процессоры начинают выполнять следующий сверхшаг.
Будучи интересной абстрактной моделью, BSP также стала моделью программирования.
В частности, в Oxford Parallel Application Center реализованы библиотека взаимодействия и набор протоколирующих инструментов, основанные на модели BSP. Библиотека состоит примерно из 20 функций, в которых поддерживается BSP-стиль обмена сообщениями и удаленный доступ к памяти.
LogP
Модель LogP является более современной. Она учитывает характеристики машин с распределенной памятью и содержит больше деталей, связанных со свойствами выполнения в коммуникационных сетях, чем модель BSP. Процессоры в LogP асинхронные, а не син-
476 Часть 3. Синхронное параллельное программирование
хронные. Компонентами модели являются процессоры, локальная память и соединительная сеть. Свое название модель получила от прописных букв своих параметров:
• L — верхняя граница задержки (Latency) при передаче сообщения, состоящего из одного слова, от одного процессора к другому;
• о — накладные расходы (overhead), которые несет процессор, передавая сообщение (в течение этого времени процессор не может выполнять другие операции);
• g — минимальный временной интервал (gap) между последовательными отправками или получениями сообщений в процессоре;
• Р — число пар процессор-память.
Единицей измерения времени является длительность основного цикла процессоров. Предполагается, что длина сообщений невелика, а сеть имеет конечную пропускную способность, т.е. одновременно между процессорами передаются не более Г L/gl сообщений.
Модель LogP описывает свойства выполнения в коммуникационной сети, но не ее структуру. Таким образом, она позволяет моделировать взаимодействие в алгоритме. Однако промоделировать время локальных вычислений нельзя. Такой выбор был сделан, поскольку, во-первых, при этом сохраняется простота модели, и, во-вторых, локальное (последовательное) время выполнения алгоритмов в процессорах легко устанавливается и без этой модели.
12.3.6. Учебные примеры: быстродействующий Фортран (НРБ)
Быстродействующий Фортран (High-Performance Fortran — HPF) — это самый новый пред ставитель семейства языков, основанных на Фортране. Первая версия HPF была создана многими разработчиками из университетских, промышленных и правительственных лабораторий в 1992 г. Вторая версия была опубликована в начале 1997 г. Несколько компиляторов существуют и сейчас, а HPF-программы могут работать на основных типах быстродействующих машин.
HPF — это язык, параллельный по данным. Он является расширением Фортрана 90, последовательного языка, поддерживающего ряд операций с массивами и их частями. На проект HPF повлиял Фортран D, более ранний диалект Фортрана, параллельный по данным. Основные компоненты HPF: параллельное по данным присваивание массивов, директивы компилятора для управления распределением данных-и операторы для записи и синхронизации параллельных циклов. Ниже рассматривается каждый из этих компонентов языка и приводится законченная программа для метода итераций Якоби.

Оба присваивания массивов имеют семантику параллельности по данным: сначала вычисляется правая часть, затем все значения присваиваются левой части. В первом присваивании значение в каждой внутренней точке new устанавливается равным среднему арифметическому значений ее четырех соседей в grid. Во втором присваивании массив new копируется обратно в grid. В действительности тело этого цикла можно было бы запрограммировать так.
Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 477
grid(2:n-l,2:n-l) =
(grid(l:n-2,2:n-l) + grid(3:n, 2:n-l) + grid(2:n-l,l:n-2) + grid(2:n-l,3:n)) / 4
Один и тот же массив может появляться в обеих частях — это обусловлено параллельностью по данным семантики присваивания массивов. Однако в коде, сгенерированном компилятором для этого оператора, все равно придется использовать временную матрицу, например new.
Перед присваиванием массивов может стоять выражение WHERE, задающее условные операции с массивами, например приращение только положительных элементов.
В языке HPF есть также операторы редукции, которые неделимым образом применяют какую-либо операцию ко всем элементам массива и возвращают скалярное значение. Наконец, HPF обеспечивает ряд так называемых встроенных (intrinsic) функций, которые работают с целыми массивами. Например, функция TRANSPOSE (а) вычисляет транспозицию массива а. Другая функция, CSHIFT, обычно применяется для выполнения циклического смещения данных в массиве; в последнем примере правая часть в присваивании grid представляет собой набор смещенных версий grid.
Отображение данных
В языке HPF директивы отображения данных позволяют программисту управлять расположением данных, в частности, их локализацией, особенно на машинах с распределенной памятью. Директивы являются рекомендациями компилятору HPF, т.е. не императивами, которым необходимо следовать, а советами, которые, по мнению программиста, улучшают производительность. В действительности удаление из программы всех директив отображения данных никак не повлияет на результат вычислений; просто программа, возможно, не будет работать столь эффективно.
Основные директивы — processors, align и distribute. Директива processors определяет форму и размер виртуальной машины процессоров Директива выравнивания align определяет взаимно однозначное соответствие между элементами двух массивов, указывая на то, что они должны быть выровнены и одинаково распределены. Директива DISTRIBUTE определяет, каким способом массив (и все выровненные с ним) должен отображаться в памяти виртуальной машины, определенной ранее директивой PROCESSORS; эти два способа обозначаются с помощью BLOCK (блоки) и CYCLIC (полосы).
В качестве примера предположим, что position и force— векторы, скажем, в задаче имитации п тел, и рассмотрим следующий код.
!HPF$ PROCESSORS pr(8)
!HPF$ ALIGN position (:) WITH force (:)
!HPF$ DISTRIBUTE position(CYCLIC) ONTO pr
Первая директива определяет абстрактную машину с восемью процессорами, вторая — задает выравнивание position относительно force.
В третьей директиве указано, что вектор position должен отображаться на процессоры циклически (по полосам); соответственно, вектор force будет точно так же поделен на полосы между процессорами.
HPF поддерживает дополнительные директивы отображения данных. TEMPLATE — абстрактная область индексов, которую можно использовать в качестве целевой для директив выравнивания и источника для директивы распределения. Директива DYNAMIC указывает, что выравнивание или распределение массива может изменяться во время! работы программы
С ПОМОЩЬЮ директивы REALIGN ИЛИ REDISTRIBUTE.
Параллельные циклы
Присваивания массивов в HPF имеют параллельную по данным семантику и, следовательно, могут выполняться параллельно. HPF также обеспечивает два механизма задания параллельных циклов.
478 Часть 3. Синхронное параллельное программирование
Оператор FORALL указывает, что тело цикла должно выполняться параллельно. Например, в следующем цикле параллельно вычисляются все новые значения в grid.
FORALL (i=2:n-l, j=2:n-l)
new(i,j) = (grid(i-l,j) + grid(i+l,j) +
grid(i,j-l) + grid(i,j+l)) / 4
Результат здесь такой же, как и при присваивании массивов. Однако тело цикла в операторе FORALL может состоять более, чем из одного оператора. Индексы цикла могут также иметь маску для задания предиката, которому должны удовлетворять индексные значения; это обеспечивает возможности, подобные тем, которые предоставляет оператор WHERE, но при этом отпадает необходимость окружать тело цикла операторами if.
Вторым механизмом написания параллельных циклов является директива INDEPENDENT. Программист, помещая ее перед циклом do, утверждает, что тела циклов независимы и, следовательно, могут выполняться параллельно. Например, в коде
!HPF$ INDEPENDENT do i = l,n
A(lndex(i)) = B(i) end
программист утверждает, что все элементы Index (i) различны (не имеют псевдонимов) и А и В не перекрываются в памяти.
Если В — функция, а не массив, программист может также использовать директиву pure, чтобы объявить об отсутствии побочных эффектов в в.
Пример: метод итераций Якоби
В листинге 12.5 представлена законченная HPF-подпрограмма для метода итераций Якоби. В ней используется несколько механизмов, описанных выше. Первые три директивы определяют, что матрицы grid и new должны быть выровнены по отношению друг к другу и располагаться на PR процессорах блоками. Значение PR должно быть статической константой. В теле вычислительного цикла параллельно обновляются все точки матрицы, затем new также параллельно копируется в grid. Когда главный цикл завершается, в последнем присваивании вычисляется максимальная разница между соответствующими друг другу значениями в grid и new. Неявные барьеры установлены после оператора FORALL, оператора копирования массива и оператора редукции массива.

Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 479
Сравните эту программу с явно параллельной программой в листинге 11.2 и программе использующей библиотеку ОрепМР (см. листинг 12.4). Данный код намного короче благод! ря семантике параллельности по данным языка HPF. С другой стороны, явно параллельны код, подобный кодам в листингах 11.2 и 12.4, должен генерировать компилятор HPF. Это ь слишком трудно для данного приложения и машин с разделенной памятью. Но для машины распределенной памятью создать хороший код гораздо сложнее. Например, программа с яв ным обменом сообщениями для метода итераций Якоби (см. листинг 11.4) полностью отли чается от приведенной выше программы. Компилятор HPF должен распределить данные ме жду процессорами и сгенерировать код с обменом сообщениями. Директивы ALIG, и DISTRIBUTE дают ему указания, как это делать.