Библиотеки параллельного программирования
Библиотеки параллельного программирования представляют собой набор подпрограмм, обеспечивающих создание процессов, управление ими, взаимодействие и синхронизацию. Эти подпрограммы, и особенно их реализация, зависят от того, какой вид параллельности поддерживает библиотека — с разделяемыми переменными или с обменом сообщениями.
При создании программ с разделяемыми переменными на языке С обычно используют стандартную библиотеку Pthreads. При использовании обмена сообщениями стандартными считаются библиотеки MPI и PVM; обе они имеют широко используемые общедоступные реализации, которые поддерживают как С, так и Фортран. ОрепМР является новым стандартом программирования с разделяемыми переменными, который реализован основными производителями быстродействующих машин. В отличие от Pthreads, ОрепМР является набором директив компилятора и подпрограмм, имеет связывание, соответствующее языку Фортран, и обеспечивает поддержку вычислений, параллельных по данным. Далее в разделе показано, как запрограммировать метод итераций Якоби с помощью библиотек Pthreads и MPI, а также директив ОрепМР.
12.1.1. Учебный пример: Pthreads
Библиотека Pthreads была представлена в разделе 4.6, где рассматривались подпрограммы для использования потоков и семафоров. В разделе 5.5 были описаны и проиллюстрированы подпрограммы для блокировки и условных переменных. Эти механизмы можно использовать и в программе, реализующей метод итераций Якоби (листинг 12.1) и полученной непосредственно из программы с разделяемыми переменными (см. листинг 11.2). Как обычно в программах, использующих Pthreads, главная подпрограмма инициализирует атрибуты потока, читает аргументы из командной строки, инициализирует глобальные переменные и создает рабочие процессы. После того как завершаются вычисления в рабочих процессах, главная программа выдает результаты.




Программа в листинге 12.2 содержит три функции: main, Coordinator и Worker. Предполагается, что выполняются все numWorkers+1 экземпляров программы. (Они запускаются с помощью команд, специфичных для конкретной версии MPI.) Каждый экземпляр начинается с выполнения подпрограммы main, которая инициализирует MPI и считывает аргументы командной строки.
Затем в зависимости от номера (идентификатора) экземпляра из main шзывается либо управляющий процесс Coordinator, либо рабочий Worker.
Каждый процесс worker отвечает за полосу "точек. Сначала он инициализирует обе свои гетки и определяет своих соседей, left и right. Затем рабочие многократно обмениваются с соседями краями своих полос и обновляют свои точки. После numlters циклов обмена-обновления каждый рабочий отправляет строки своей полосы управляющему процессу, вычисляет максимальную разность между парами точек на своей полосе и, наконец, вызывает MPl_Reduce, чтобы отправить mydiff управляющему процессу.
Процесс Coordinator просто собирает результаты, отправляемые рабочими процессами. Сначала он получает строки окончательной сетки от всех рабочих. Затем вызывает под-
454 Часть 3. Синхронное параллельное программирование
программу MPl_Reduce, чтобы получить и сократить максимальные разности, вычисленные каждым рабочим процессом. Заметим, что аргументы в вызовах MPi_Reduce одинаковы и в рабочих, и в управляющем процессах. Предпоследний аргумент COORDINATOR задает, что редукция должна происходить в управляющем процессе.
12.1.3. Учебный пример: ОрепМР
ОрепМР — это набор директив компилятора и библиотечных подпрограмм, используемых для выражения параллельности с разделением памяти. Прикладные программные интерфейсы (APIs) для ОрепМР были разработаны группой, представлявшей основных производителей быстродействующего аппаратного и программного обеспечения. Интерфейс Фортрана был определен в конце 1997 года, интерфейс C/C++ — в конце 1998, но стандартизация обоих продолжается. Интерфейсы поддерживают одни и те же функции, но выражаются по-разному из-за лингвистических различий между Фортраном, С и C++.
Интерфейс ОрепМР в основном образован набором директив компилятора. Программист добавляет их в последовательную программу, чтобы указать компилятору, какие части программы должны выполняться параллельно, и задать точки синхронизации.
Директивы можно добавлять постепенно, поэтому ОрепМР обеспечивает распараллеливание существующего программного обеспечения. Эти свойства ОрепМР отличают ее от библиотек Pthread и MPI, которые содержат подпрограммы, вызываемые из последовательной программы и компонуемые с нею, и требуют от программиста вручную распределять работу между процессами.
Ниже описано и проиллюстрировано использование ОрепМР для Фортран-программ. Вначале представлена последовательная программа для метода итераций Якоби. Затем в нее добавлены директивы ОрепМР, выражающие параллельность. В конце раздела кратко описаны дополнительные директивы и интерфейс C/C++.
В листинге 12.3 представлен эскиз последовательной программы для метода итераций Якоби. Ее синтаксис своеобразен, поскольку программа написана с использованием соглашений Фортрана по представлению данных с фиксированной точкой. Строки с комментариями начинаются с буквы с в первой колонке, а декларации и операторы — с колонки 7. Дополнительные комментарии начинаются символом !. Все комментарии продолжаются до конца строки.


Последовательная программа состоит из двух подпрограмм: main и jacobi. В подпрограмме main считываются значения п (размер сетки с границами) и maxiters (максимальное число итераций), а затем вызывается подпрограмма jacobi. Значения данных хранятся в общей области памяти и, следовательно, неявно передаются из main в jacobi. Это позволяет jacobi распределять память для массивов grid и new динамически.
В подпрограмме jacobi реализован последовательный алгоритм, представленный выше влистинге 11.1. Основное различие между программами в листингах 12.3 и 11.1 обусловлено синтаксическим отличием псевдо-С от Фортрана. В Фортране нижняя граница каждой размерности массива равна 1, поэтому индексы внутренних точек матриц по строкам и столбцам принимают значения от 2 до п-1. Кроме того, Фортран сохраняет матрицы в памяти машины по столбцам, поэтому во вложенных циклах do сначала выполняются итерации по столбцам, а затем по строкам.
В ОрепМР используется модель выполнения "разветвление-слияние" (fork-join). Вначале существует один поток выполнения. Встретив одну из директив parallel, компилятор вставляет код, чтобы разделить один поток на несколько подпотоков. Вместе главный поток и подпотоки образуют так называемое множество рабочих потоков. Действительное количество рабочих потоков устанавливается компилятором (по умолчанию) или определяется пользователем — либо статически с помощью переменных среды (environment), либо динамически с помощью вызова подпрограммы из библиотеки ОрепМР.
Чтобы распараллелить программу с помощью ОрепМР, программист сначала определяет части программы, которые могут выполняться параллельно, например циклы, и окружает их директивами parallel и end parallel. Каждый рабочий поток выполняет этот код, обрабатывая разные подмножества в пространстве итераций (для циклов, параллельных по данным) или вызывая разные подпрограммы (для программ, параллельных по задачам). Затем в программу добавляются дополнительные директивы для синхронизации потоков во время выполнения. Таким образом, компилятор отвечает за разделение потоков и распределение работы между ними (в циклах), а программист должен обеспечить достаточную синхронизацию.
В качестве конкретного примера рассмотрим следующий последовательный код, в котором внутренние точки grid и new инициализируются нулями.
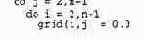

Каждая директива компилятора начинается с ! $отр. Первая определяет начало параллельного цикла do. Вторая дополняет первую, что обозначено добавлением символа & к ! $отр. Во второй директиве сообщается, что во всех рабочих потоках n, grid и new являются разделяемыми переменными, a i и j — локальными. Последняя директива указывает на конец параллельного цикла do и устанавливает точку неявной барьерной синхронизации,
В данном примере компилятор разделит итерации внешнего цикла do (no j) и назначит их рабочим процессам некоторым способом, зависящим от реализации.
Чтобы управлять назначением, программист может добавить предложение schedule. В ОрепМР поддерживаются различные виды назначения, в том числе по блокам, по полосам (циклически) и динамически (портфель задач). Каждый рабочий поток будет выполнять внутренний цикл do (no i) для назначенных ему столбцов.
В листинге 12.4 представлен один из способов распараллеливания тела подпрограммы j acobi с использованием директив ОрепМР. Основной поток разделяется на рабочие потоки для инициализации сеток, как было показано выше. Однако maxdif f инициализируется в основном потоке. Инициализация maxdif f перенесена, поскольку ее желательно выполнить в одном потоке до начала вычислений максимальной погрешности. (Вместо этого можно было бы использовать директиву single, обсуждаемую ниже.)
После инициализации разделяемых переменных следует директива parallel, разделяющая основной поток на несколько рабочих. В следующих двух предложениях указано, какие переменные являются общими, а какие — локальными. Каждый рабочий выполняет главный цикл. В цикл добавлены директивы do для указания, что итерации внешних циклов, обновляющие grid и new, должны быть разделены между рабочими. Окончания этих циклов обозначены директивами end do, которые также обеспечивают неявные барьеры.
После главного цикла (который завершается одновременно всеми рабочими) используется еще одна директива do, чтобы максимальная погрешность вычислялась параллельно. В этом разделе maxdif f используется в качестве переменной редукции, поэтому к директиве do добавлено предложение reduction. Семантика переменной редукции такова, что каждое обновление является неделимым (в данном примере с помощью функции max). В действительности ОрепМР реализует переменную редукции, используя скрытые переменные в каждом рабочем потоке; значения этих переменных "сливаются" неделимым образом в одно на неявном барьере в конце распараллеленного цикла.
Программа в листинге 12.4 иллюстрирует наиболее важные директивы ОрепМР.
Библио тека содержит несколько дополнительных директив для распараллеливания, синхронизации и управления рабочей средой (data environment). Например, для обеспечения более полного управления синхронизацией операторов можно использовать следующие директивы.
critical Выполнить блок операторов как критическую секцию. atomic Выполнить один оператор неделимым образом.
Глава 12. Языки, компиляторы, библиотеки и инструментальные средства 457
s ingle В одном рабочем потоке выполнить блок операторов. barrier Выполнить барьер, установленный для всех рабочих потоков.
В ОрепМР есть несколько библиотечных подпрограмм для запросов к рабочей среде и управления ею. Например, есть подпрограммы установки числа рабочих потоков и его динамического изменения, а также определения идентификатора потока.

458 Часть 3 Синхронное параллельное программирование
Ключевое слово pragma обозначает директиву компилятора. Поскольку в С вместо циклов do для определенного количества итераций используются циклы for, эквивалентом директивы do в С является
pragma omp for clauses.
В интерфейсе C/C++ нет директивы end. Вместо нее блоки кода заключаются в фигурные скобки, обозначающие область действия директив.